[KDD'08] Factorization meets the neighborhood: a multifaceted collaborative filtering model
Introduction
추천 시스템은 종종 과거 사용자 행동에만 의존하고 명시적인 프로필 작성이 필요하지 않은 CF를 기반으로 합니다.
이는 도메인 지식이 필요하지 않고 광범위한 데이터 수집이 필요하지 않으며 예상치 못한 패턴을 찾을 수 있습니다.
그 결과로 아마존, TiVo 및 넷플릭스를 포함한 일부 상업 시스템에 채택되었습니다.
Collaborative Filtering 시스템은 기본적으로 서로 다른 대상(사용자에 대한 항목)을 비교해야 됩니다.
이를 쉽게 하기 위해서는 크게 두 가지로 접근할 수 있습니다.
1) Neighborhood approach
이는 항목 간 또는 사용자 간의 관계를 계산하는 것이 핵심입니다.
item-oriented approach는 동일한 사용자에 의한 유사한 item의 평가를 기반으로 item에 대한 사용자의 선호도를 평가합니다.
이는 매우 지역화된 관계를 탐지하는데 효과적입니다.
2) Latent Factor Model
SVD와 같은 latent factor model은 항목과 사용자를 동일한 latent factor space로 변환해 직접 비교함으로써 대안적인 접근 방식을 구성합니다.
이 latent space는 사용자의 피드백에서 자동으로 추론되는 요인에 대해 제품과 사용자를 특성화하여 등급을 설명하려고 합니다.
이는 모든 항목과 동시에 과련된 전체 구조를 추정하는데 효과적이지만 밀접하게 관련된 작은 항목 집합 간의 강한 연관성을 감지하는데 어려움이 있습니다.
해당 연구에서는 암시적 피드백과 명시적 피드백을 함께 사용하여 이웃과 latent factor 접근 방식의 장점들을 활용해 예측의 정확도를 향상시키는 결합 모델을 제안합니다.
이는 처음 해당 연구에서 시도되었다고 합니다.
본 논문의 진행 순서는 먼저 neighborhood model과 latent factor model을 개선시키는 과정을 설명하고 이를 통합한 결과에 대한 실험을 설명하는 순서로 진행됩니다.
2. Priliminaries
1) Baseline estimates
Notation
- user: \( u, v \)
- item: \( i, j \)
- rating: \( r_{ui} \)
일부 사용자는 다른 사용자보다 더 높은 평가를 제공하고 일부 하목은 다른 사용자보다 더 높은 평가를 받는 시스템적 경향이 있습니다.
이를 위해 데이터 조정을 하게 되며 이를 기준 추정치 내에 캡슐화를 진행합니다.
먼저, 전체 평균 등급을 \( \mu \)로 표시하며 알수 없는 등급 \( r_{ui} \)에 대한 'baseline estimaties'는 \( b_{ui} \)로 표시되며 이는 다음과 같이 표현합니다.
- \( b_{ui} = \mu + b_u + b_i \)
여기서 \( b_u \)와 \( b_i \)는 각각 평균으로부터 사용자 \( u \)와 항목 \( i \)의 관측된 편차를 나타냅니다.
영화로 예시를 들어본다면, \( \mu \), 즉 전체 영화의 평균이 3.7이면서 특정 사용자가 전체적으로 영화에 대한 평점을 0.3만큼 낮게 주는 경향이 있다고 가정하겠습니다. 이때 특정 영화의 평점이 다른 영화들보다 0.2점 높게 rating되는 경향이 있다고 할 경우, 이때 \( b_{ui} =3.7-0.3+0.2 = 3.6 \) 을 만족하게 됩니다.
\( b_u \)와 \( b_i \)를 추정하기 위해서 아래의 식을 이용하여 계산합니다.

먼저 첫번째로 \( \Sigma_{(u, i) \in K} (r_{ui} -\mu +b_u + b_i)^2 \) 는 주어진 rating에 맞는 \( b_u \)와 \( b_i \)를 최적화하기 위한 수식입니다.
여기서 \( b_u \), \( b_i \) 를 제곱함으로써 모델이 너무 복잡해져 특젖ㅇ 데이터에 과적합되는 것을 방지하기 위해 bias의 크기에 페널티를 부과하는 과정이 추가되었습니다.
2) Neighborhood models
여기서의 similarity measure은 다음과 같습니다.

여기서 \( n_ij \)는 \( i, j \)를 rating한 user의 수를 의미하고 \( rho \)는 pearson corellation coefficient를 의미합니다.
이는 user가 rating한 item의 similarity의 경향을 측정하게 됩니다.
이때 전형적으로 \( \lambda_2 \)는 100을 쓴다고 합니다.
우리의 목표는 관측되지 않은 유저에 대한 \( i \)의 rating \( r_{ui} \)를 구하는 것이기 때문에 이를 이용한 식은 다음과 같습니다.

이 식의 단점은 기준이 되는 항목과 유사한 항목이 없어도 해당 가중치의 합은 1이 되기 떄문에 유사하지 않은 항목이 왜곡된 영향을 줄 수 있다는 것입니다.
그렇기에 해당 논문은 다음과 같은 방향으로 \( \hat\{r_{ui}} \)를 구하였습니다.

이는 interporation weights \( \{ \theta^u_{ij} | j \in S^k(i;u)\} \)를 이용하여 구한 것으로 여기서의 \( S^k(i;u) \)는 이웃 집합입니다.
3) Latent factor models
latent factor model은 일반적으로 SVD를 활용한다고 합니다.
Notation
- \( p_u \in R^f \): user vector
- \( q_i \in R^f \): item vector
- prediction: \( r_{ui} = b_{ui} + p _u^T q_i \)
일단 CF에서 SVD를 도입하는 것은 sparse한 rating 때문에 어렵다고 합니다.
일단 전통적인 SVD 모델은 매트릭스에 대한 지식이 불완전한 경우 정의되지 않습니다.
게다가 소수의 항목만 부주의하게 해결할 경우 overfitting되기 쉽다고 합니다.
그렇기에 최근의 연구들은 이 missing된 rating을 채우고 rating matrix를 dense하게 채우기 위해 imputation에 의존했습니다.
그러나 imputation은 데이터의 양을 크게 늘리기 때문에 cost 문제가 있습니다.
그래서 최근의 연구들은 이 overfitting을 피하기 위해 아래와 같이 진행하였습니다.

이는 simple gradient descent technique를 사용하여 관찰된 등급만 직접 모델링을 하게 됩니다.
Paterek는 NSVD를 제안하였는데 이는 다음과 같은 수식으로 이루어져있습니다.

여기서 \( x_j \)는 item latent vector이며 \( R(u) \)는 user가 rating을 남긴 item 집합을 의미합니다.
이렇게 \( \sqrt{|R(u)|}를 나눔으로써 user가 소비한 item이 많을 시 user vector의 크기가 지나치게 커지는 것을 방지해줍니다.
본 논문에서는 해당 idea를 adapt하였습니다.
4) Dataset
본 논문에서는 Netflix dataset을 사용하였고 explicit data는 유저가 남긴 rating을 사용, implicit data는 user가 영화를 본 기록과 평가 여부(1: 평가함, 0: 평가하지 않음)을 사용하였다고 합니다.
3. A neighborhood model
해당 파트에서는 본 논문이 neighborhood model을 발전시킨 방향에 대해 순서대로 설명을 할 것이며 마지막으로 설명하는 내용을 최종적으로 채택했다고 합니다.

첫 번째 수식입니다.
앞의 (4) 수식과 달라진점은 interpolation weights가 \( w_{ij} \)로 대체되었다는 것입니다.
\( w_{ij} \)는 j로부터의 i의 weight를 뜻하며 해당 수식의 개선된점은 다음과 같습니다.
먼저 가중치를 사용자마다 item i, j의 similarity weight sum을 따로 계산하지 않고 item i, j의 관계를 직접 계산하였다는 점과 user가 rating을 한 모든 아이템을 \( R(u) \)를 계산 과정에 포함하였다는 점으로 말할 수 있겠습니다.
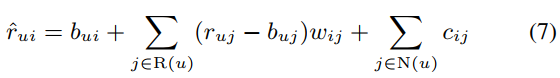
두 번째 수식입니다.
여기서의 개선된 점은 뒤에 \( \Sigma_{j \in N(u)} c_{ij} \)가 붙었다는 것인데요
\( N(u) \)는 user가 소비한 item의 정보를 의미하며 즉 implicit data를 계산 과정에 포함하게 되었습니다.
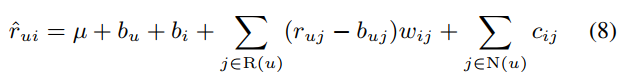
이는 위와 같이 쓸 수 있습니다.
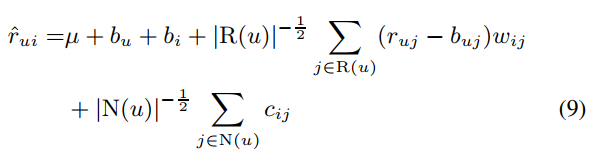
세 번째 수식입니다.
이전의 수식에서는 영화를 많이 본 사용자(여기서는 heavy rater라고 표현)은 시청한 영화에 따라 더 많은 항들이 계산에 추가되고, 영화를 적게 본 사용자는 baseline 예측치에서 크게 벗어나지 않는 구조였습니다.
이를 개선하기 위해 \( |R(u)|^{-\frac{1}{2}} \), \( |N(u)|^{-\frac{1}{2}} \) 를 곱하여 평가를 많이 한 사용자와 적게 한 사용자 간 양극화를 완화하였습니다.
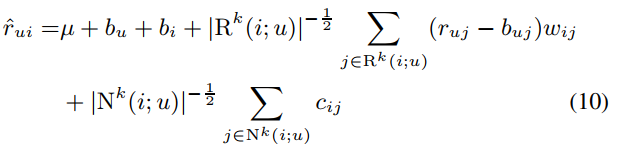
네 번째, 즉 최종적인 수식입니다.
이는 \( |R(u)|^{-\frac{1}{2}} \), \( |N(u)|^{-\frac{1}{2}} \) 를 \( |R^K(i;u)|^{-\frac{1}{2}} \), \( |N^K(i;u) |^{-\frac{1}{2}} \) 로 바꾸었는데 이는 모든 이웃 아이템을 사용하지 않고 item \( i \)와 유사한 k개의 item 중에서 user가 소비한 item만을 사용하여 계산하였습니다.
이때 k를 무한대로 보낼경우, 9번 식과 같은 결과가 나오게 됩니다.
해당 파라미터를 (10)과 관련된 least squares problem을 해결함으로써 학습됩니다.
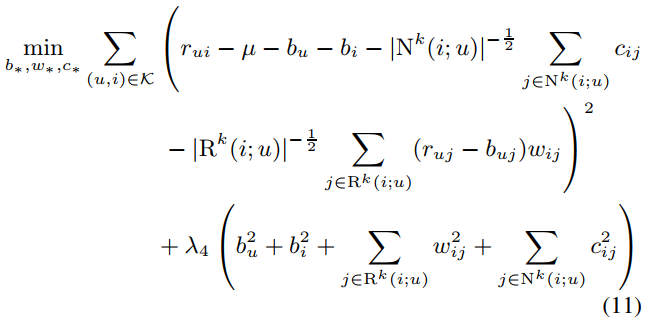
위에서 구한 모델에 대한 RMSE 값을 구하였는데 그 결과 new model(11)이 가장 좋은 결과를 보인 것을 확인할 수 있었습니다.
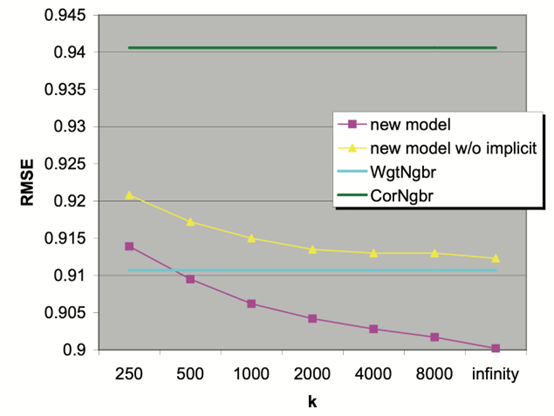
4. Latent factor models
다음은 Latent factor model입니다.
앞에서 NSVD 모델을 채택했다고 하였는데 이를 다음과 같이 변형하였습니다.
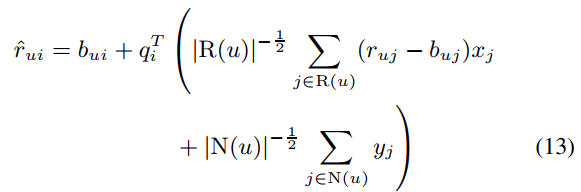
이 식은 기존 모델과 달리 explicit data를 사용할 뿐만 아니라 implicit data까지 활용하여 user의 latent factor를 계산하게 되었고 이 식을 Asymmetric SVD라고 합니다.
여기서는 user가 소비한 item을 통해 user를 표현하였고 이를 통해 다음과 같은 이점을 얻었습니다.
- Fewer paramters
: 일반적으로 user의 수가 item 수보다 많은데 item을 통해 user를 표현함으로써 parameter 개수를 줄였습니다. - New users
: 새로운 user가 들어오게 될 경우 user가 소비한 item으로 user를 표현하기 때문에 새로운 user가 들어와도 모델과 paramter를 새롭게 학습할 필요가 없습니다. - Explainability
: user가 소비한 item을 이용하여 user를 구성하는 것은 직관력있고 설명력이 있습니다. - Efficient integration of implicit feedback
: implicit feedback를 고려하였기에 예측의 정확도가 향상되었습니다.
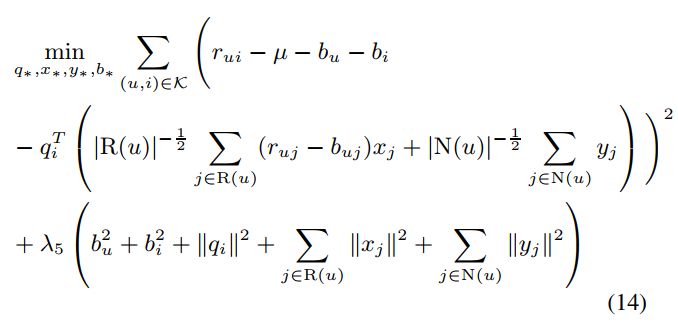
이는 위의 수식으로 parameter를 학습하였다고 합니다.

Asymmetric SVD의 경우 실제로 SVD보다 더 우수한 성능을 보였습니다.
여기서 SVD++가 추가된 모습을 볼 수 있는데 SVD++는 implicit feedback만 사용하면서 user-factors vector \( p_u \)를 사용한 모델입니다.
SVD++의 수식은 다음과 같습니다.
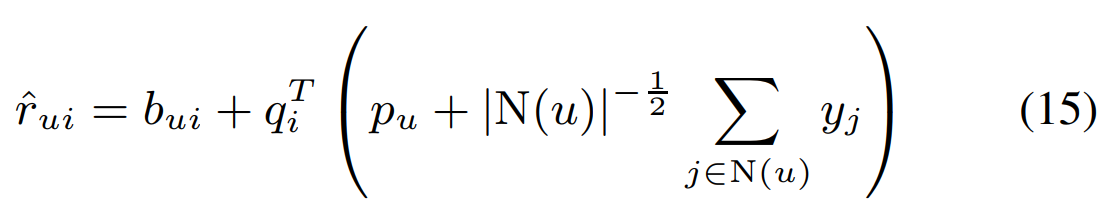
해당 모델은 user-factors vector를 사용하기 때문에 앞서 Asymmetric SVD의 장점이라고 설명한 'fewer paramters'에 대한 장점은 살리지 못한 모델입니다.
하지만 Table1에서 SVD++의 성능이 가장 우수한 모습을 볼 수 있습니다.
그렇기에 해당 논문에서 Latent factor model을 SVD++를 채택하였습니다.
An integrated model
introduction에서 본 논문은 neighborhood model과 latent factor model의 장점을 둘 다 살려 모델을 제안한다고 하였습니다.
그렇기에 (10), (15)를 합친 모델 (16)을 제안합니다.
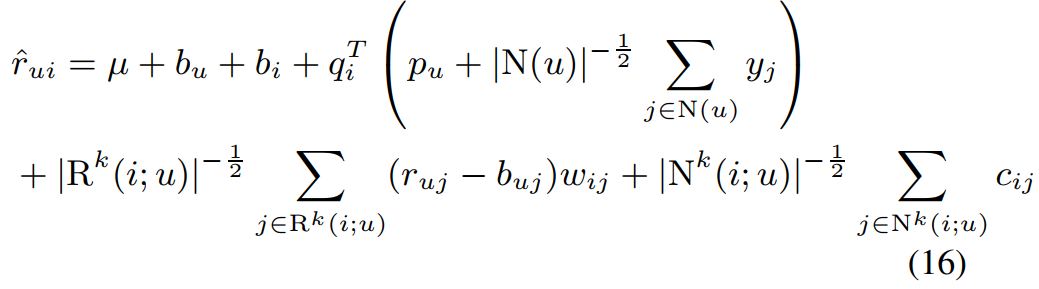
해당 식의 paramter는 다음과 같은 과정을 통해 학습되었습니다.
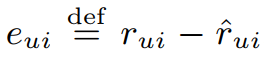
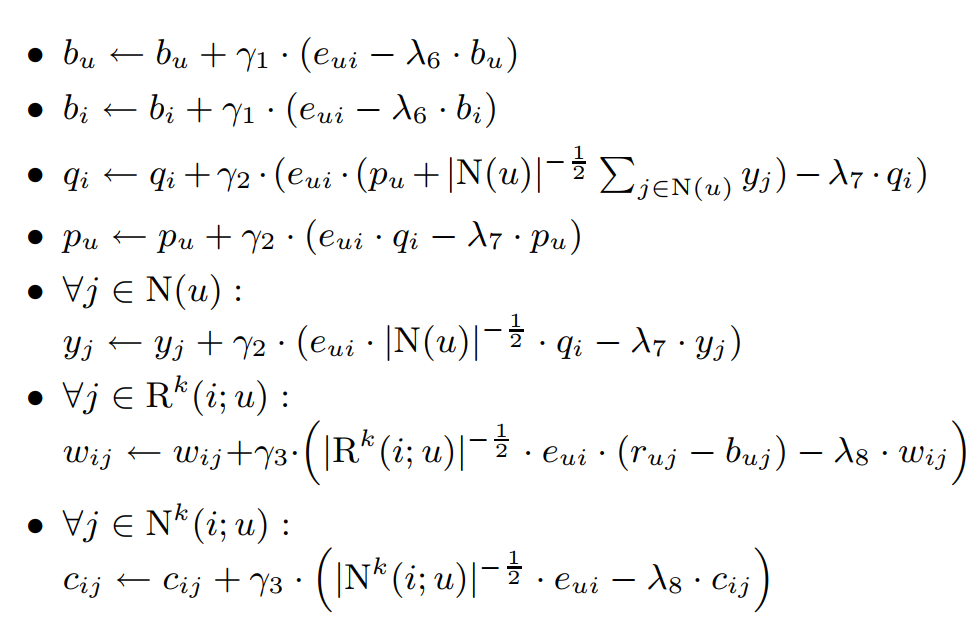

실험 결과입니다.
Baseline의 RMSE 값은 0.9514인 반면, 통합 모델의 경우 더 최적화를 시켰을 때 0.8645까지 낮췄다고 합니다.
본 논문은 여기서 마치지 않고 이 RMSE 값이 낮아지는 것이 top-k recommedation에 얼마나 큰 영향을 주는지 알아봅니다.
이를 위해 top-k evaluation을 진행하여 계산을 해본 결과, 다음과 같은 결과가 나왔습니다.
Top-k evaluation 과정
- Netflix dataset의 Test dataset에서, 특정 user가 5점 평점을 준 영화를 하나 고르고, 같은 user가 평점을 준 영화 중, 5점을 받지 않은 1000개의 영화를 고릅니다.
- 학습된 추천 모델을 이용해 1001개의 영화에 대해 평점을 예측하게 하고, 예측된 평점이 높은 순으로 순위를 매깁니다.
- Test dataset의 \( r_ui=5 \)를 만족하는 모든 384,573개의 평점에 대해 같은 과정을 반복합니다.
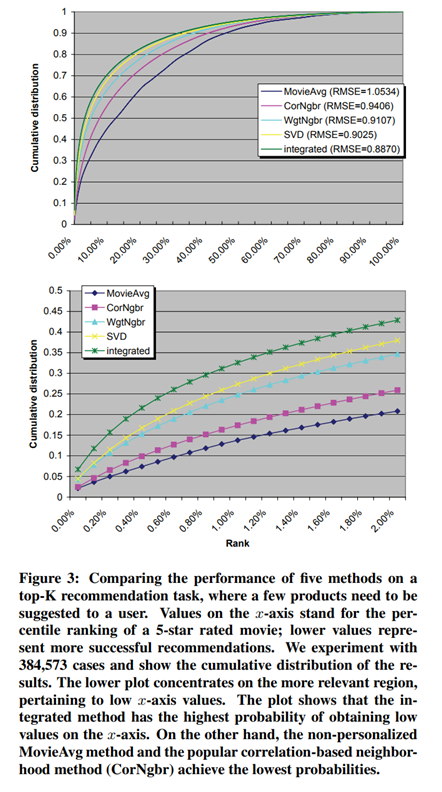
y축은 0%부터 100%까지 모든 데이터에 대한 누적 분포(높은 순위를 매긴 5점 item의 비율이 높은 것)이며 y축의 값이 높을수록 모델의 성능이 우수함을 의미합니다.
아래의 그래프는 위의 그래프를 확대한 모습이며 실질적으로 의미가 있는 뷰를 보기 위해 확대했다고 합니다.
그 결과 통합된 모델이 가장 좋은 성능을 보였으며 다른 모델과 2~3배의 차이를 보였습니다.
그렇기에 통합된 모델, 즉 낮은 RMSE 값을 가진 모델이 실제 추천에서도 성능 향상을 보였다고 합니다.