
더보기
TL;DR
이 문서는 RAG(Retrieval-Augmented Generation)에 대한 최적의 방법을 탐색하고, 각 모듈에 대한 가장 효과적인 접근 방식을 제안합니다. Query Classification 모듈, Retrieval 모듈, Reranking 모듈, Repacking 모듈, Summarization 모듈에 대한 최적의 방법을 제시하며, Multimodal Extension 및 Limitations에 대해서도 다룹니다.
https://arxiv.org/abs/2407.01219
[Searching for Best Practices in Retrieval-Augmented Generation
Retrieval-augmented generation (RAG) techniques have proven to be effective in integrating up-to-date information, mitigating hallucinations, and enhancing response quality, particularly in specialized domains. While many RAG approaches have been proposed
arxiv.org](https://arxiv.org/abs/2407.01219)
0. Abstract
기존의 RAG는 구현이 복잡하고 응답시간이 오래 걸린다는 단점이 있다.
기존의 RAG 접근 방식과, 잠재적인 조합을 조사해 최적의 RAG 방식을 파악하고자 한다.
1. Introduction
생성형 LLM은 강화 학습 또는 다양한 방법을 통해 인간의 선호도에 맞게 조정되었지만, 오래된 정보를 생성하거나 사실을 조작 하는 경우가 있음
Retrieval-Augmented Generation(RAG)란 사전 학습과 검색 기반 모델의 강점을 합해 해당 문제를 해결함으로써 모델의 성능을 향상시킬 수 있는 프레임 워크를 말함
RAG를 사용할 경우 특정 조직과 도메인에 대한 애플리케이션을 신속히 배포할 수 있음
일반적인 RAG의 워크플로우는 아래와 같음:

- Query Classification: ‘주어진 입력 쿼리에 대해 검색이 필요한가?’에 대한 여부를 결정하는 과정
- Retrieval: 쿼리와 관련된 문서를 효율적으로 획득하는 과정
- Reranking: 쿼리와의 관련성에 따라 검색된 문서의 순서를 재조정하는 과정
- Repacking: 검색된 문서를 구조화된 문서로 구성해 더 나은 생성을 함
- Summarization: Repacking된 문서에서 응답 생성용 핵심 정보를 추출하고 중복을 제거하는 과정
해당 과정에서는 문서의 chunk를 적절히 분할하는 방법, 청크를 의미론적으로 표현하는데 사용할 임베딩 유형, feature 표현을 효율적으로 저장할 벡터 DB의 선택, LLM을 효과적으로 fine-tuning하는 방법에 대한 결정이 필요함
이전 연구
1. 쿼리를 먼저 생성한 뒤, 재작성된 쿼리를 검색에 사용
2. 쿼리에 대한 응답을 먼저 생성한 뒤, 이 응답과 백엔드 문서간의 유사성을 비교하여 검색
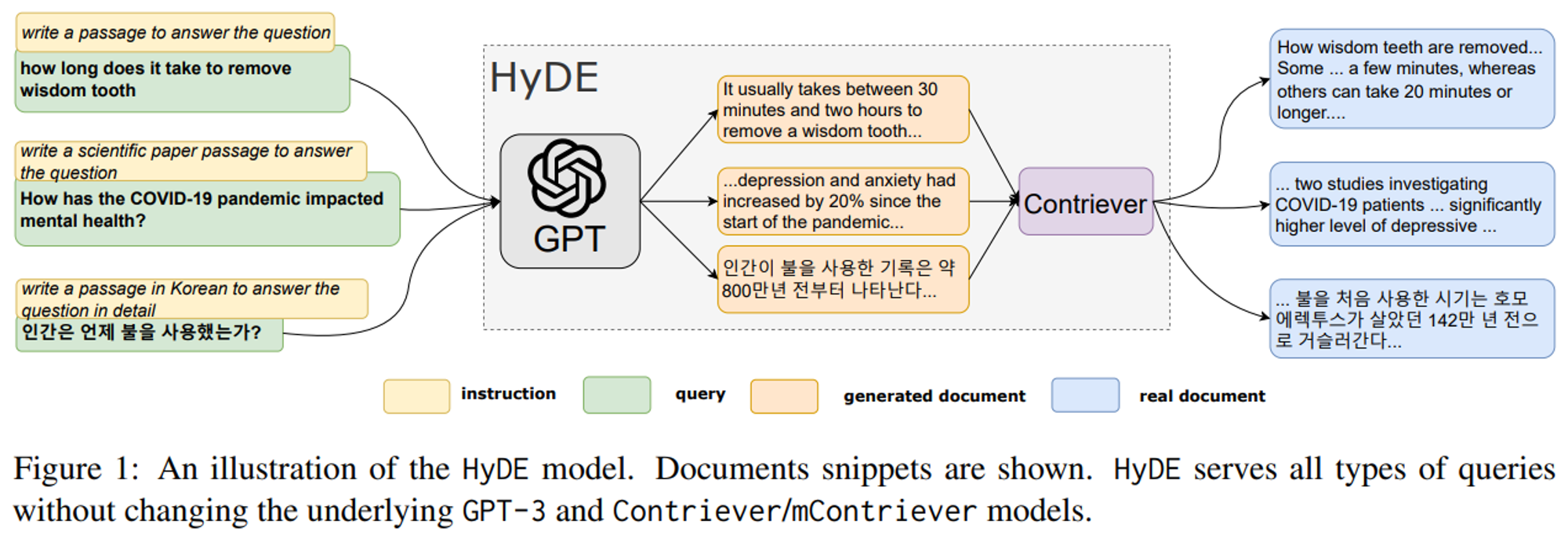
3. positive-negative query-response 쌍을 사용하여 대조적인 방식으로 학습
이전 연구를 보면, RAG 워크플로우에 대해 최적의 RAG를 구현하기 위한 체계적인 노력이 없었음
그렇기에 본 논문은 3가지 접근 방식을 채택함
- RAG의 대표적인 방법을 비교해 가장 성과가 좋은 방법 중 최대 세 가지를 선택
- 개별 단계에 대해 한 번에 하나의 방법을 테스트하고 다른 RAG 모듈을 변경하지 않은 상태에서 각 방법이 전체 RAG 성능에 미치는 영향을 평가
- 이를 통해 응답 생성 중 각 단계의 기여도와 다른 모듈과의 상호작용을 기반으로 각 단계에서 가장 효과적인 방법을 결정
- 성능보다 효율성이 우선시되거나, 그 반대의 경우가 발생할 수 있는 다양한 시나리오에 접근
Contribution
- 최적의 RAG 방식을 선별
- 포괄적인 평가 메트릭 및 해당 데이터 셋을 소개, 일반, 전문(혹은 도메인 별) 및 RAG 관련 기능을 다룸
- 멀티 모달 검색 기술을 통합하여 시각적 입력에 대한 질문 답변 기능을 크게 개선, 멀티 모달의 생성 속도를 높일 수 있음을 입증
2. Related Work
일단! LLM에서 생성된 응답은 hallucination이 발생하는 것을 근본적으로 해결할 수 없음.
RAG는 이 문제를 외부 Knowledge Base로부터 관련 문서를 검색해 이 현상 해결함
이전 연구에서는 모두 아래의 기법들을 사용해 fine-tuning을 통해 파이프라인을 최적화
2.1. Query and Retrieval Transformation
1. 원본 쿼리에 pseudo-doc를 생성해 검색을 향상시킴
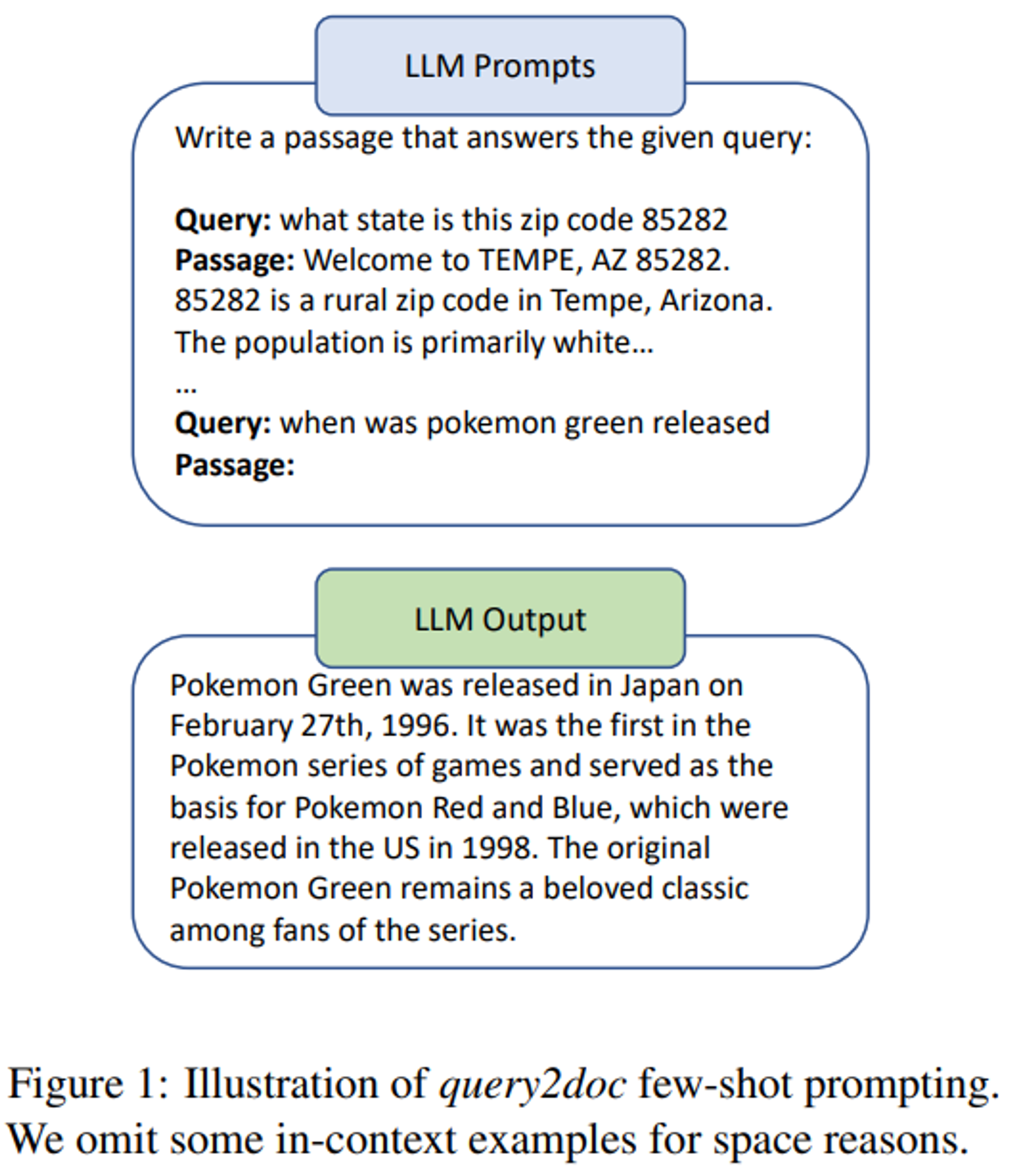
2. 쿼리를 하위 쿼리로 분해해 검색된 콘텐츠를 집계
3. 검색 문서에 대한 pseudo-query를 생성하는 인터페이스를 제공해 실제 쿼리와의 매칭을 개선(LlamaIndex)
4. Contrasitive learing을 통해 쿼리와 문서 임베딩을 semantic space에서 더 가깝게 만듦
5. 검색된 문서를 후처리

2.2. Retriever Enhancement Strategy
문서의 청킹은 retriever 성능에 큰 영향을 끼침
작은 청크로 나눌 경우: 문장을 파편화 할 수 있음
큰 청크로 나눌 경우: 관련 없는 문맥을 포함할 수 있음
LlamaIndex는 청킹 방식으로 최적화를 진행
# query
"What is the significance of the number 227 in 'Life of Pi'?"
# output
Window: Owen Chase, whose
account of the sinking of the whaling ship Essex by a whale inspired Herman Melville, survived eighty-three
days at sea with two mates, interrupted by a one-week stay on an inhospitable island. The Bailey family
survived 118 days. I have heard of a Korean merchant sailor named Poon, I believe, who survived the Pacific
for 173 days in the 1950s.
I survived 227 days. That's how long my trial lasted, over seven months.
I kept myself busy. That was one key to my survival.
------------------
Original Sentence: "I survived 227 days."
---
# without retriever
****"The number 227 in 'Life of Pi' represents the total number of days Pi spent at sea on the lifeboat with Richard Parker."더 확장된 해석을 제공
TILDE는 쿼리 용어의 likelihood를 미리 계산해 저장하고 합계에 따라 문서의 순위를 매김
2.3. Retriever and Generator Fine-tuning
RAG에서 fine-tuning은 retriver, generator 모두를 최적화 하는데 중요함
- 컨텍스트를 더 잘 활용하도록 generator를 fine-tuning
- retriver가 generator에 유익한 구절을 검색하는 방법을 학습
- RAG를 통합 시스템으로 간주해 둘 다 fine-tuning → complexity, integration 문제가 발생
3. RAG Workflow
일반적으로 사용되는 접근 방식을 검토 및 대체 방법 선택
3.1. Query Classification
모든 쿼리에 검색 증강이 필요한 것이 아니기 때문에 이를 분류해 검색의 필요성을 결정
검색은 일반적으로 모델의 파라미터를 넘어서는 지식이 필요할 때 권장됨
Example)
“Sora was developed by OpenAI”을 번역해줘 → RAG 필요하지 않음
“Sora was developed by OpenAI” 주제에 대한 소개 요청 → 관련 정보를 제공하기 위한 검색이 필요함
총 15개의 카테고리를 가지고있으며 아래와 같이 RAG가 필요한 상황을 분류함
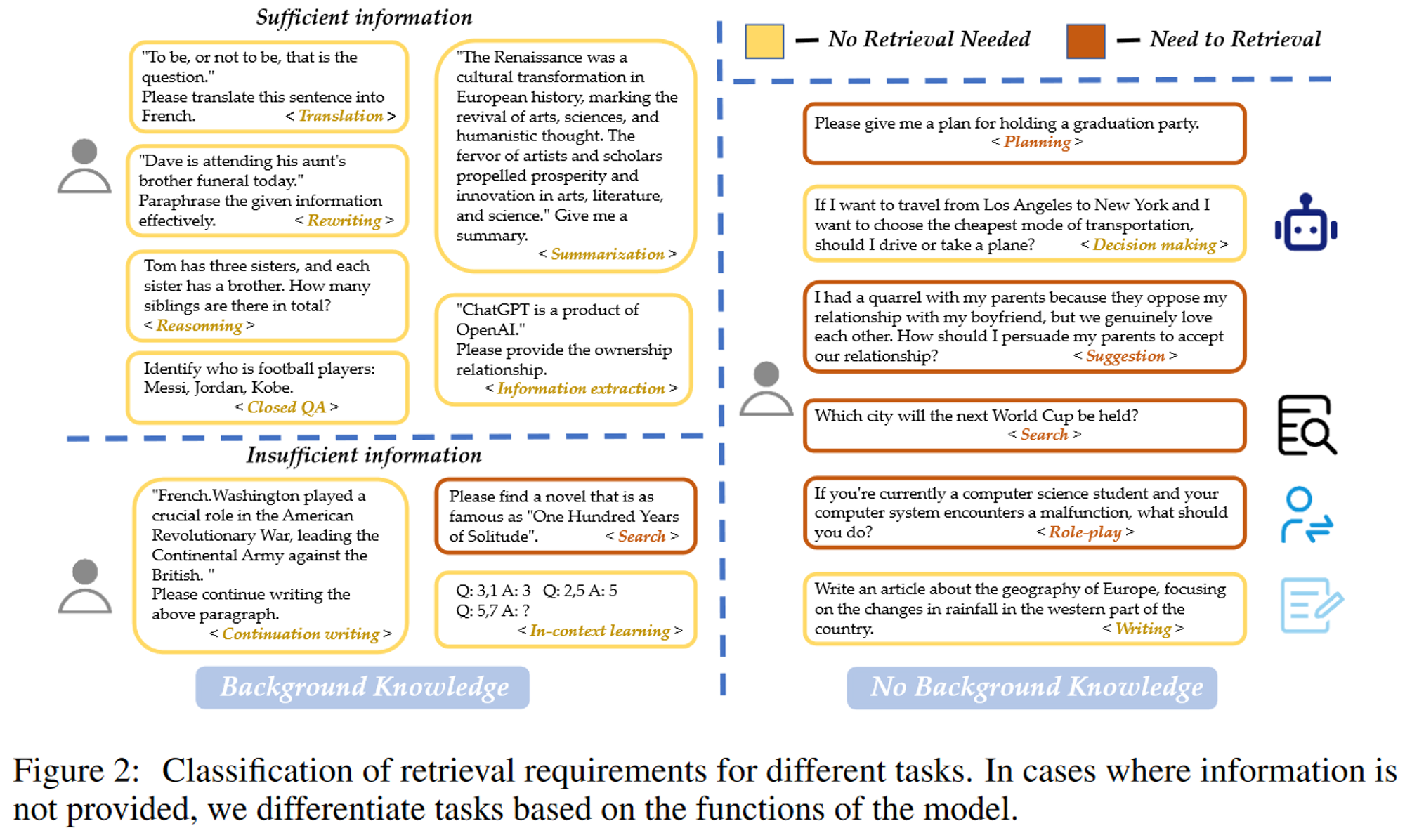
정리를 하자면
- Search, Planning, Suggestion, Role-play
- RAG가 필요함
- Translation, Rewriting, Reasoning, Closed QA, Summarization, Information extraction, Continuation writing, In-context learning, Decision making, Writing
- RAG가 필요하지 않음
3.2. Chunking
문서를 더 작은 segment로 자르는 것은 검색의 정확도를 높이고 LLM에서 길이 문제를 피하는데 중요한 역할을 함
- Token-level Chunking
- Pros: 간단함
- Cons: 검색 품질에 영향을 미침
- Semantic-level Chunking
- LLM을 사용해 중단점을 결정
- Pros: Context를 보존함
- Cons: 시간이 오래 걸림
- Sentence-level Chunking
- 단순성과 효율성 사이의 균형을 유지함
- 해당 연구에서 사용
Chunking에 대해 4가지 차원으로 알아보기
3.2.1. Chunk Size
청크 사이즈가 커지면 더 많은 컨테스트 제공하지만 처리 시간이 늘어남
청크 사이즈가 작으면 retrerival recall이 향상, 시간이 단축되지만 충분한 컨텍스트가 부족할 수 있음
최적의 청크 크기를 찾기 위해선 faithfuless나 relevancy와 같은 메트릭 간 균형을 고려해야됨
- faithfulness: response에 hallucination이 있는지, 검색된 텍스트와 일치하는지를 측정
- relevancy: 검색된 테스트와 응답이 쿼리와 일치하는지
- 실험 평가 모듈: LlamaIndex
- size of the chunk overlap: 20
- model
- zephyr-7b-alpha
- gpt-3.5-turbo
- document: 60페이지짜리 문서
- method: 선택된 corpus에 따라 약 170개의 query를 생성하도록 LLM에게 요청
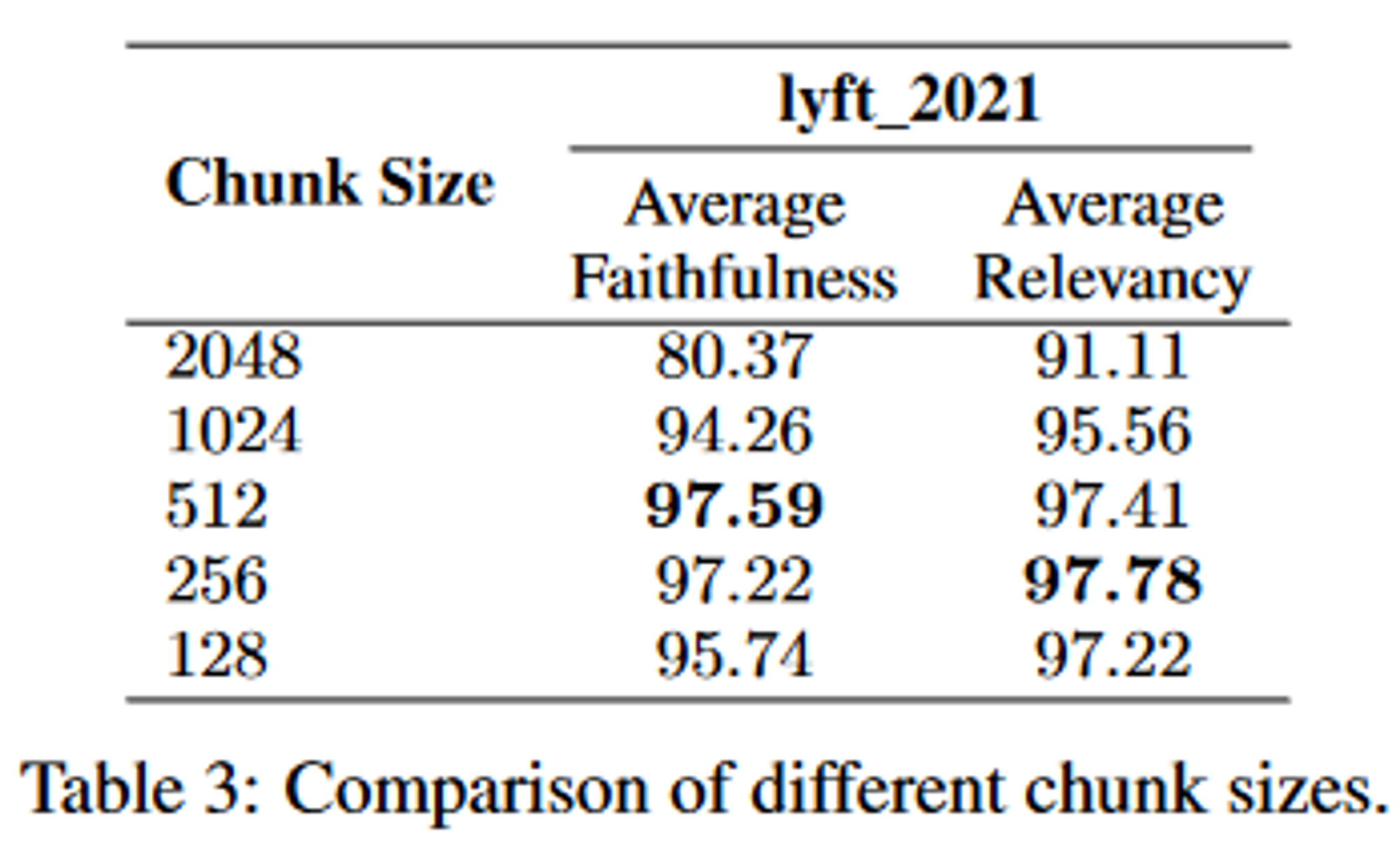
3.2.2. Chunking Techniques
small-to-big과 sliding window와 같은 기술은 청크 블록 관계를 구성해 검색 품질을 향상시키려고 함
여기서 small-to-big이란,
검색 프로세스에선 작은 텍스트 청크를 사용하고
나중에 검색된 텍스트가 LLM 속하는 큰 텍스트 청크를 제공하는 것을 말함
여기선 두 가지 기술이 쓰임
- Smaller Child Chunks Referring to Bigger Parent Chunks (더 작은 자식 청크가 더 큰 부모 청크를 참조)
- 작은 블록은 쿼리를 일치시키는데 쓰이고 작은 블록과 함께 contextual information을 포함하는 큰 블록이 반환됨
- sentence window retrieval (검색 중 단일 문장을 가져와 문장 주변의 text window를 반환)
이때 임베딩 모델은 LLM-Embedder 모델을 사용함
- smaller chunk size: 175
- larger chunk size: 512
- overlap: 20 tokens
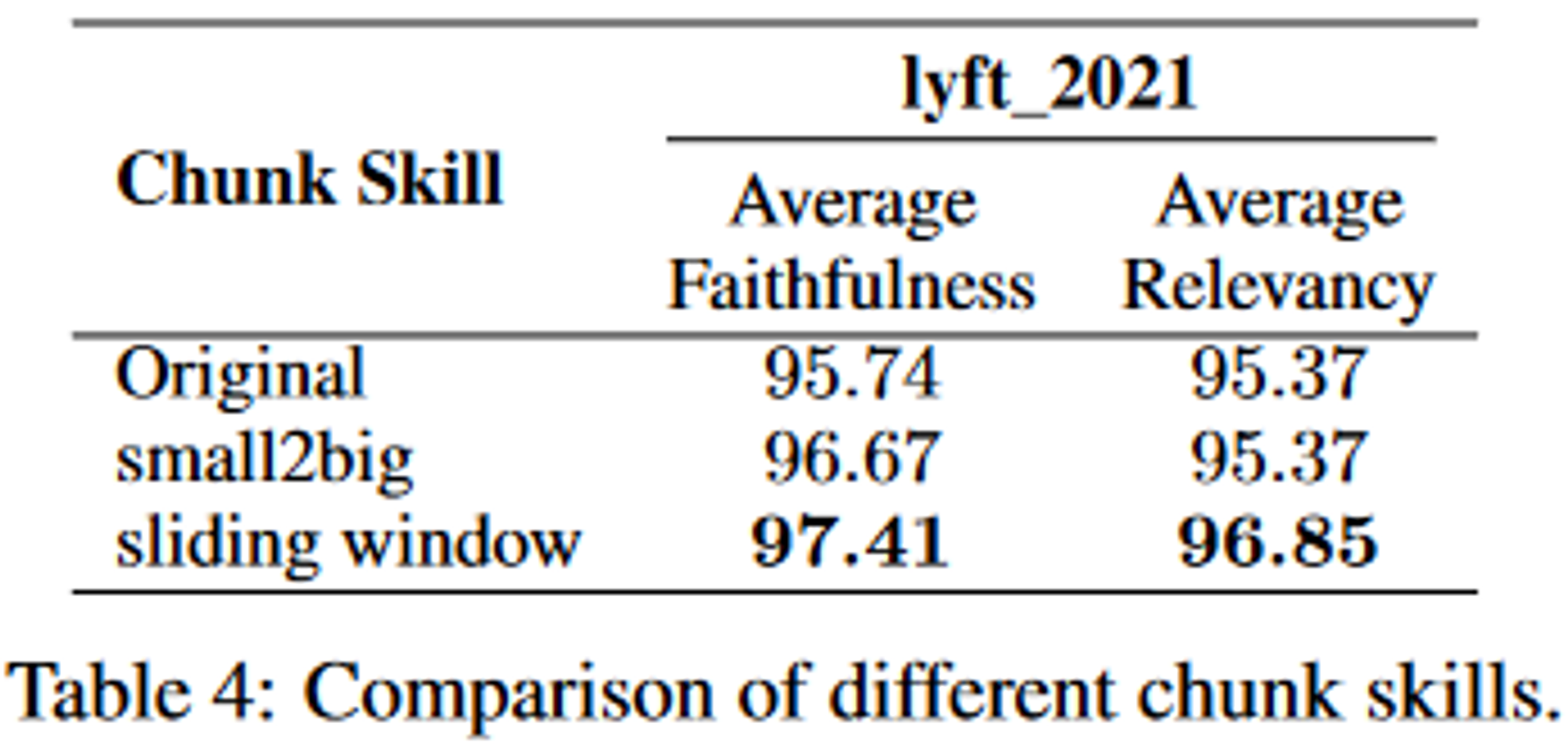
즉 이와 같은 기술을 사용해 context를 유지하고 관련 정보를 검색할 수 있게 해 검색 품질을 향상시킴
3.2.3. Embedding Model Selection
쿼리와 청크 블록 간 의미 매칭을 잘 하기 위해선 embedding 모델 선정이 중요함
- 평가 모듈: FlagEmbedding을 사용
- query: namespace-Pt/msmarco
- corpus: namespace-Pt/msmarco-corpus
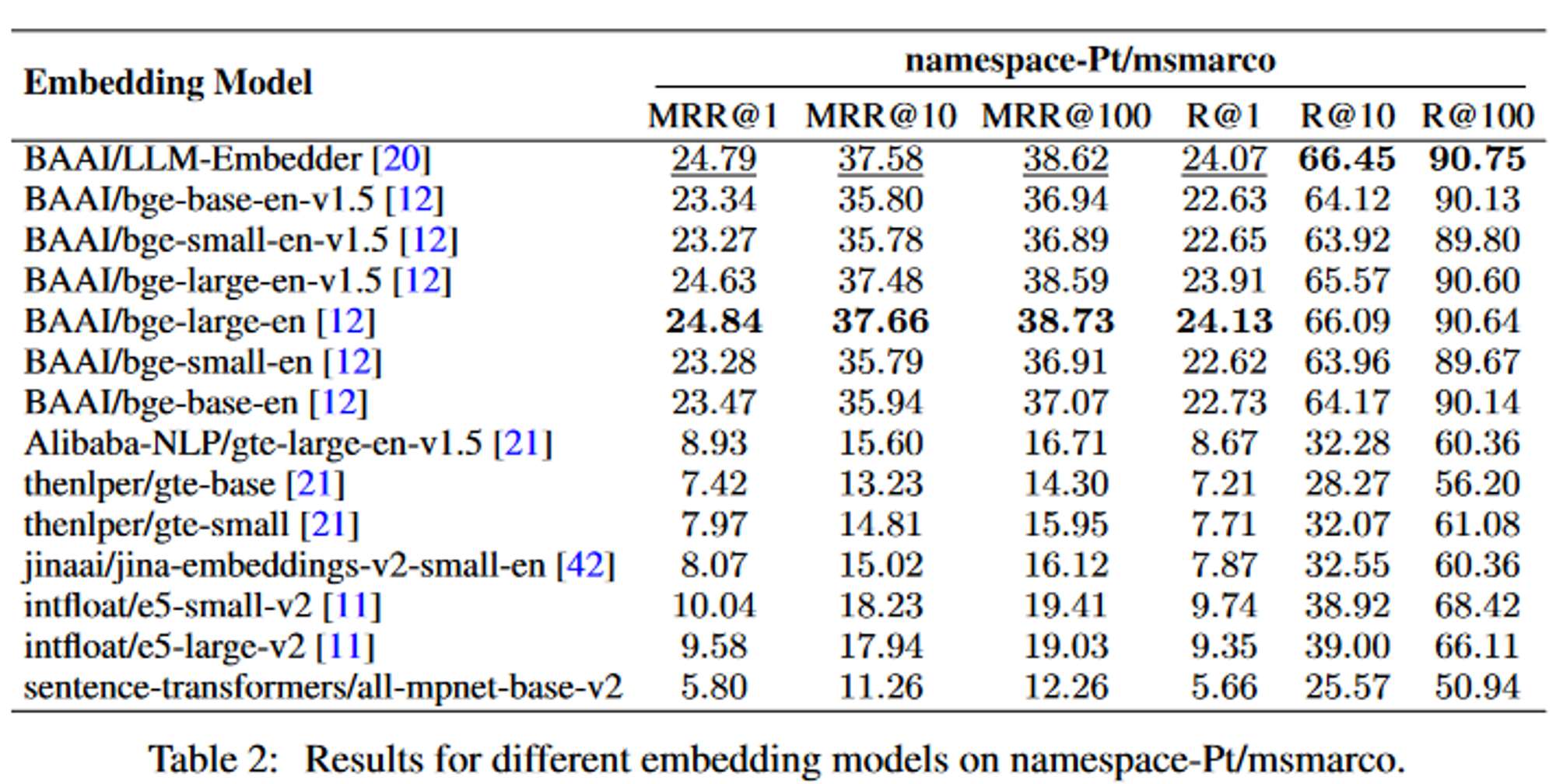
여기서 MRR은 정보 검색(Information Retrieval)의 평가 기준 중 하나로 우선 순위(Rank)를 고려하는 평가 기준임
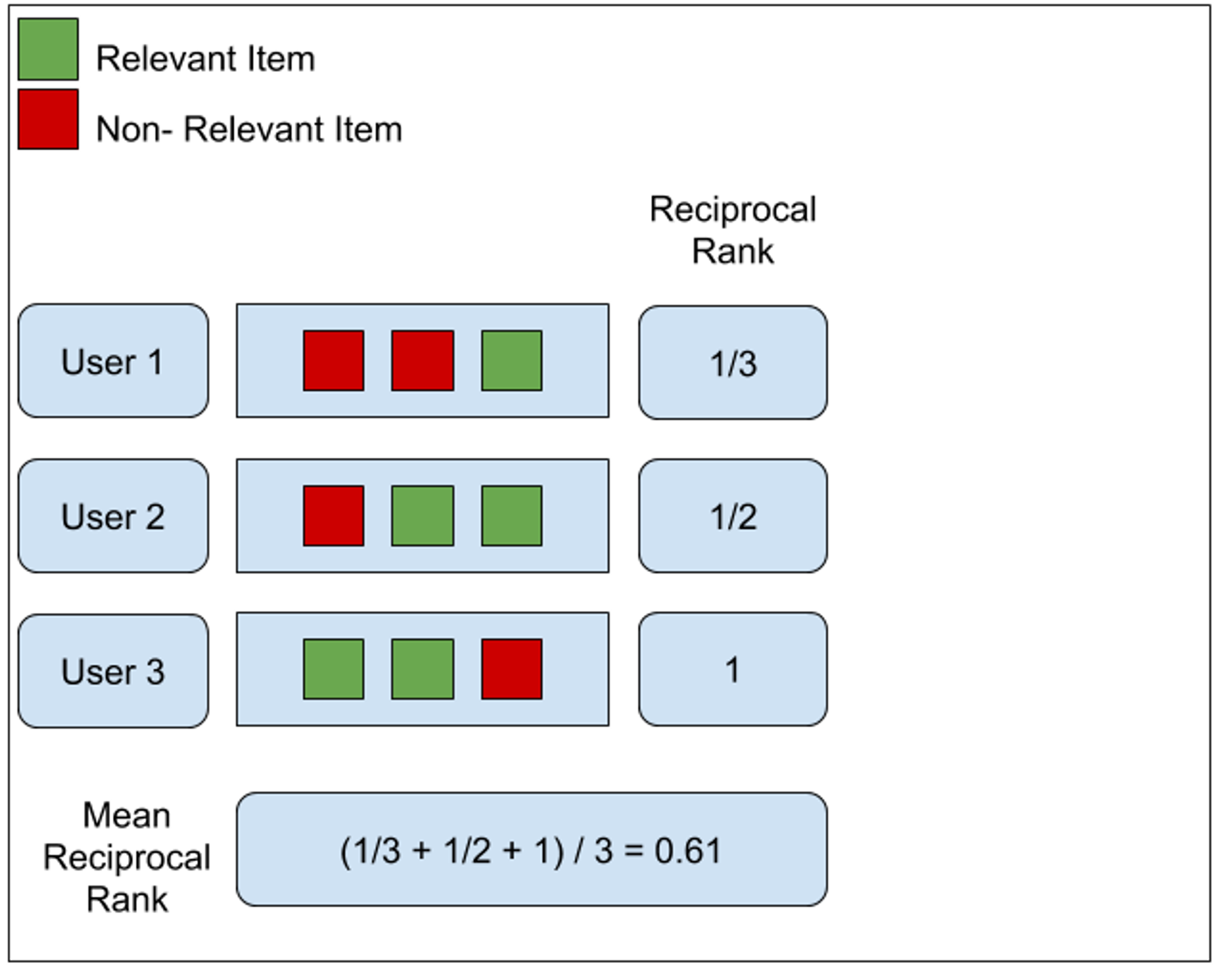
- MRR이란?
- 각 사용자마다 제공된 추천 컨텐츠에서 관련 있는 아이템 중 가장 높은 위치를 역수로 계산함
- (여기선 user1: 1/3, user2: 1/2, user3: 1/1)
- 이를 평균을 냄
- 계산 방법
여기서 LLM-Embedder는 bge-large-en과 비슷한 결과를 얻지만, model의 크기가 3배 더 작기 때문에 LLM-Embedder를 사용
3.2.4. Metadata Addition
제목, 키워드, 가상 질문을 통해 chunk block을 강화할 경우
- 검색 성능을 개선할 수 있음
- 검색된 텍스트의 후처리하는데 용이
- LLM이 검색된 정보를 더 잘 이해할 수 있도록 도움
(이는 추후 연구에서 다룰 예정)
3.3. Vector Databases
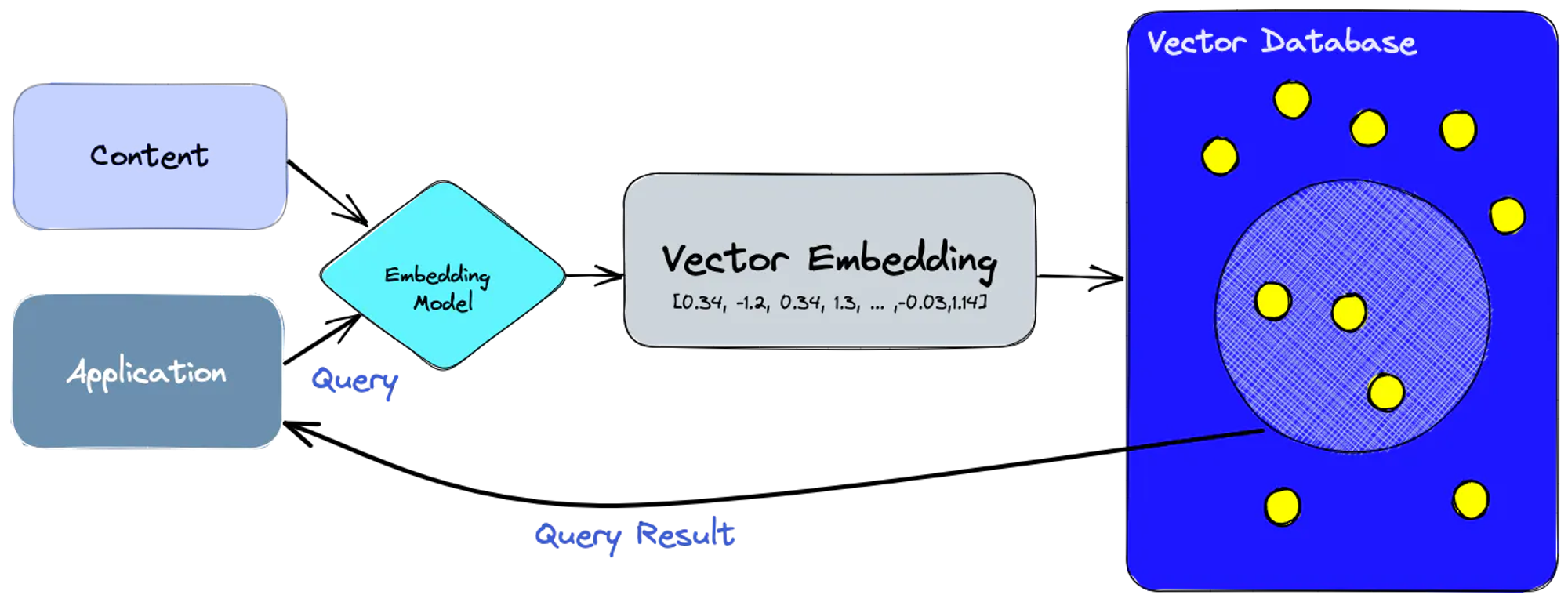
- 임베딩 모델을 사용해 indexing하려는 content에 대한 벡터 임베딩을 생성
- 벡터 임베딩은 임베딩이 생성된 원본 content를 참조해 vectorDB에 삽입됨
- 쿼리 발생시, 동일한 임베딩 모델을 사용해 쿼이에 대한 임베딩을 생성한뒤, 데이터베이스에서 유사한 벡터 임베딩을 쿼리함
다양한 인덱싱 및 Approximate Nearest Neighbor(ANN)과 같은 방법을 통해 효율적인 검색을 함
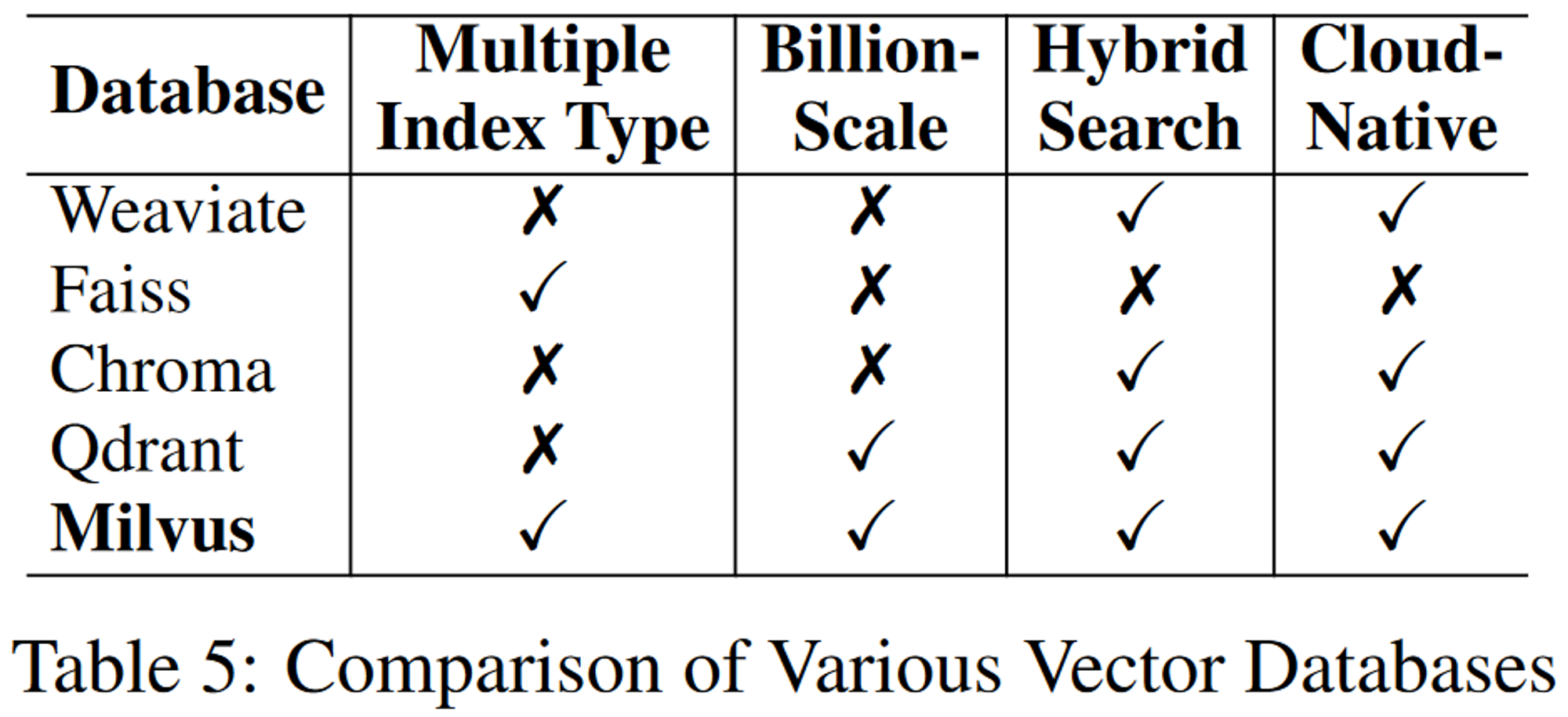
연구에 적합한 Database를 선택하기 위해서 총 4가지 기준으로 평가를 진행함
- multiple index types (여러 인덱스 유형)
- 다양한 데이터 특성과 사용 사례를 기반으로 검색을 최적화할 수 있는 flexibility 제공
- billion-scale vector support (억대 규모의 벡터 지원)
- 대규모 데이터셋 처리
- hybrid search (하이브리드 검색)
- vector search + traditional keyword search를 위함
- cloud-native capabilities (클라우드 네이티브)
- 클라우드 환경에서의 원활한 integration, scalability, management를 보장
3.4. Retrieval Methods
쿼리가 주어지면 쿼리와 문서 간 유사성을 기반으로 미리 구축된 말뭉치(corpus)에서 Top-k개의 관련 문서를 선택
이 문서를 사용해 쿼리에 대한 적절한 응답을 공식화함(formulate)
이 과정에서 쿼리의 정보가 부실할 경우 성능이 저하됨 → 이를 해결하기 위해 LLM-Embedder를 쿼리 및 document encoder로 사용해 쿼리를 변환함
- Query Rewriting
- 관련 문서와 더 유사하도록 쿼리를 개선
- Rewrite-Retrieve-Read
- 관련 문서와 더 유사하도록 쿼리를 개선
- Query Decomposition
- 기존의 쿼리에서 파생된 하위 쿼리를 기반으로 문서를 검색
- 더 복잡하고 다루기 힘들어짐
- Pseudo-documents Generation
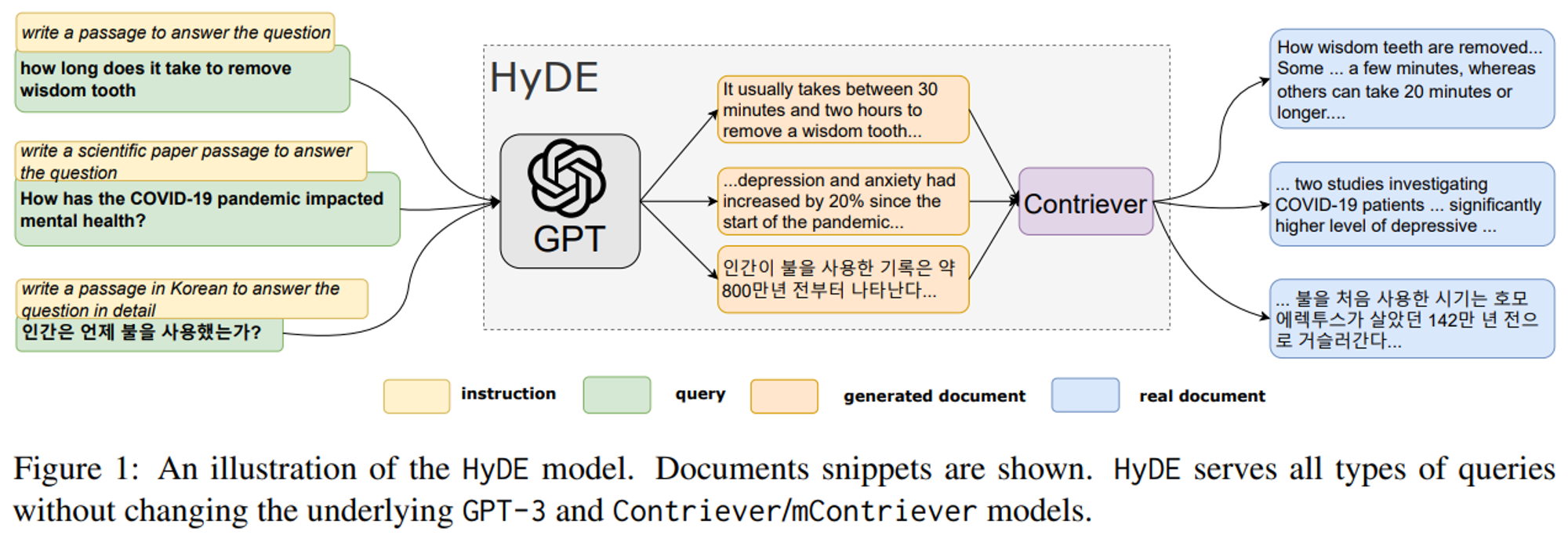
- 쿼리를 기반으로 가상의 문서를 생성해 가상의 답변 embedding과 유사한 문서를 검색 (HyDE)
최근 연구에선 lexical-based search와 vector search를 결합했을 때 성능이 크게 향상되는 것을 보임
3.4.1. Results for different retrieval methods
TREC DL 19와 TREC DL 20 데이터셋에 대해 성능을 평가해본 결과는 다음과 같음
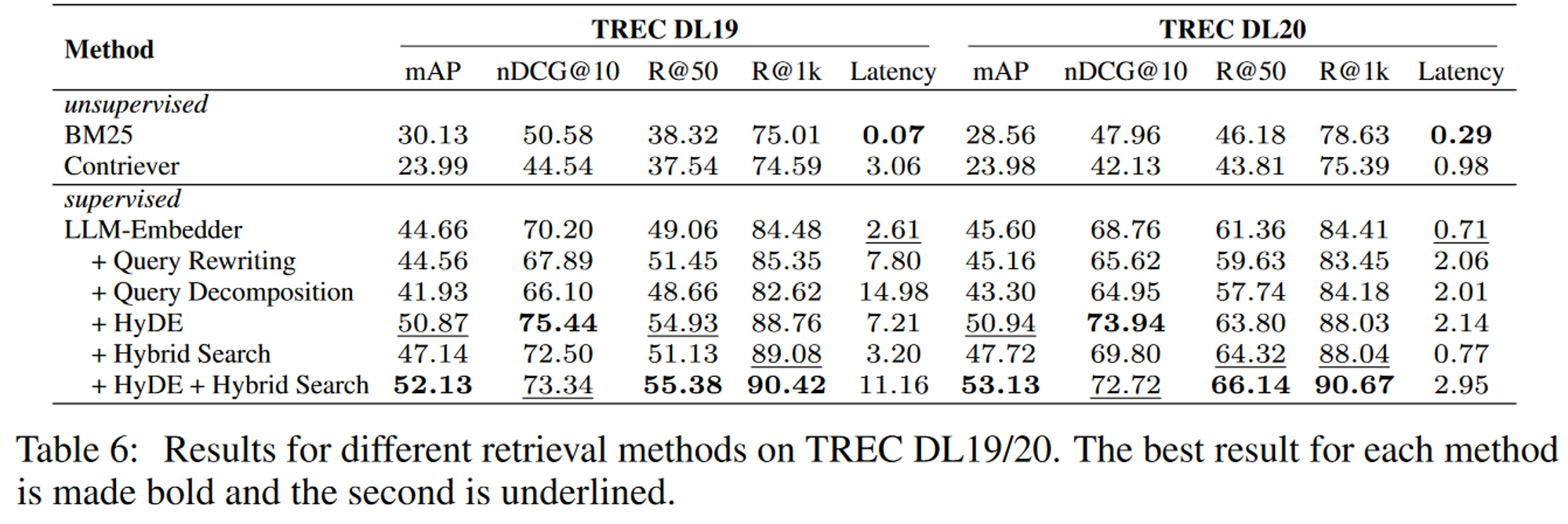
→ 지도학습이 훨씬 더 좋은 성능을 보임
HyDE와 Hybrid search를 결합한 LLM-Embedder가 가장 높은 점수를 얻었음
반면, Query Rewriting과 Query Decomposition은 그다지 좋은 성능을 보이진 못함
지연시간과 best performance를 고려했을 땐 HyDE+Hybrid Search를 쓰는 것을 추천함
- 참고
- BM25: Bag-of-words 개념으로 쿼리에 있는 용어가 문서에 얼마나 자주 등장하는지 평가하는 알고리즘
3.4.2. HyDE with Different Concatenation of Documents and Query

여러 pseudo doc을 사용하는 것은 시간과 비용은 늘어나지면 효과적인 성능 향상을 보여주지만, 큰 이점은 없고 지연시간만 크게 증가하여 하나만 사용해도 충분함
3.4.3. Hybrid Search with Different Weight on Sparse Retrieval
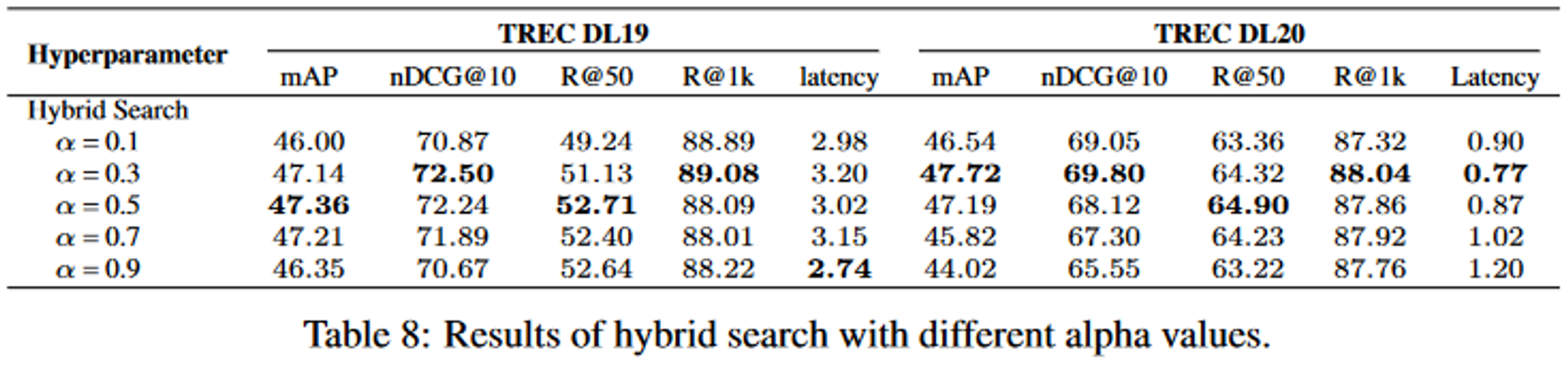
3.5. Reranking Methods
initial retrieval 후에 검색된 문서의 관련성을 높이기 위해 Reranking 단계를 거쳐 가장 관련성이 높은 정보가 맨 위에 표시되도록 함
- DLM Reranking (classification)
- 쿼리에 대한 문서의 관련성을 True/False로 분류하도록 fine-tuning됨
- 추론 과정에서는 True의 확률에 따라 순서가 매겨짐
- TILDE Reranking (query likelihood)
- 모델의 전반적인 어휘에 걸쳐 토큰의 확률을 예측해 likelihood를 독립적으로 계산
- 문서는 사전에 계산된 query token의 확률을 합산해 점수가 매겨짐
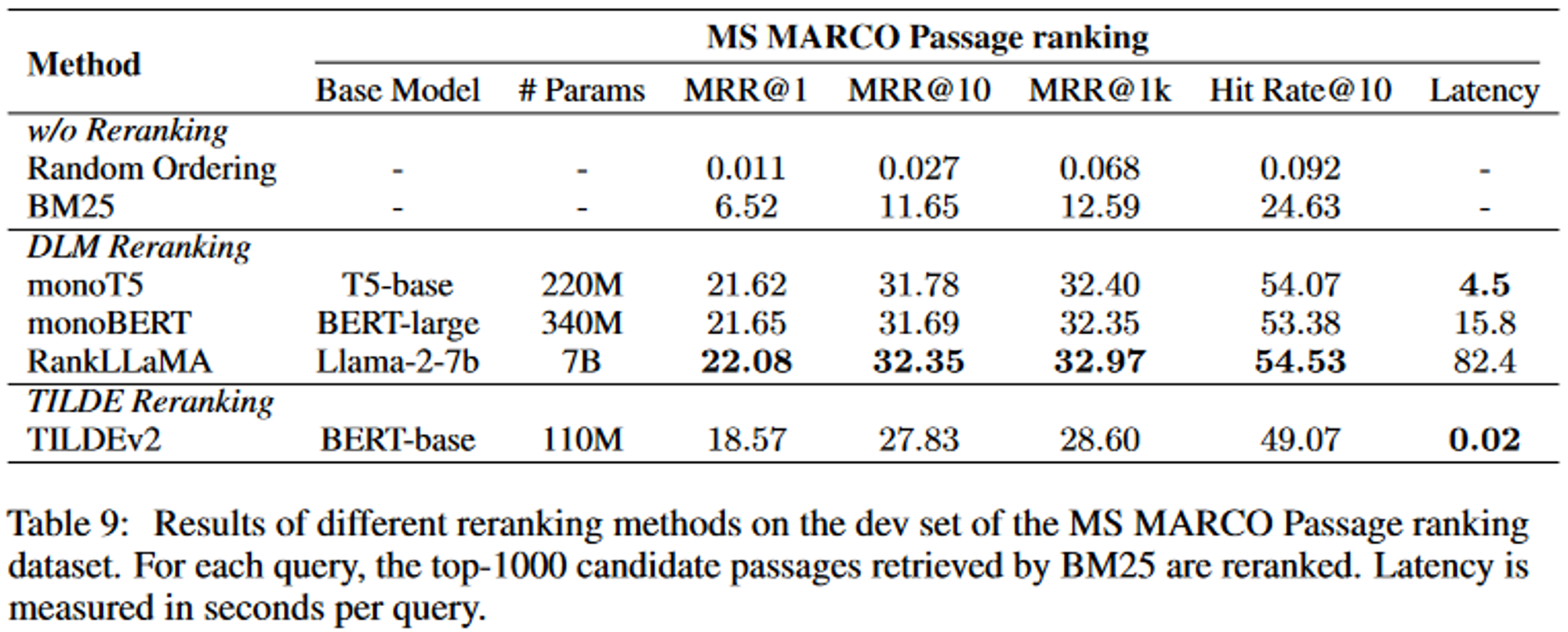
- 실험
- 데이터셋: MS MARCO Passage ranking dataset (880만개 이상의 구절과 100만개의 쿼리)
- 성능, 효율성의 균형이 적절한 방법은 momoT5를 권장함
- RankLLaMA는 최고 성능을 달성하는데 적합, TILDEv2는 고정된 컬렉션에서 가장 빠름
3.6. Document Repacking
문제: 제공되는 문서의 순서에 따라 LLM의 응답 생성과 같은 후속 프로세스의 성능이 영향을 받을 수 있음 (나비효과?)
이 문제를 해결하기 위해 Reranking을 한 뒤, “forward”, “reverse”, “sides” repacking 방법을 갖춘 repacking 모듈을 통합
- forward: reranking 단계부터 relevant score를 내림차순으로 문서를 repacking
- reverse: 오름차순으로 repacking
- sides: 관련 정보가 앞, 뒤에 배치될 때 최적의 성능을 얻을 수 있다는 연구로부터 영감을 받음
→ section 4에서 최적의 repacking 방법을 선택함
3.7. Summarization
불필요한 정보가 포함되거나, 중복된 결과가 나오면 추론 프로세스가 느려지므로 검색된 문서를 줄이는게 중요함
extractive → 텍스트를 문장으로 분할한 뒤, 중요도에 따라 점수를 매겨 순위를 매김
abstractive → 여러 문서의 정보를 합성해 문구를 바꿔 일관성있는 요약을 생성
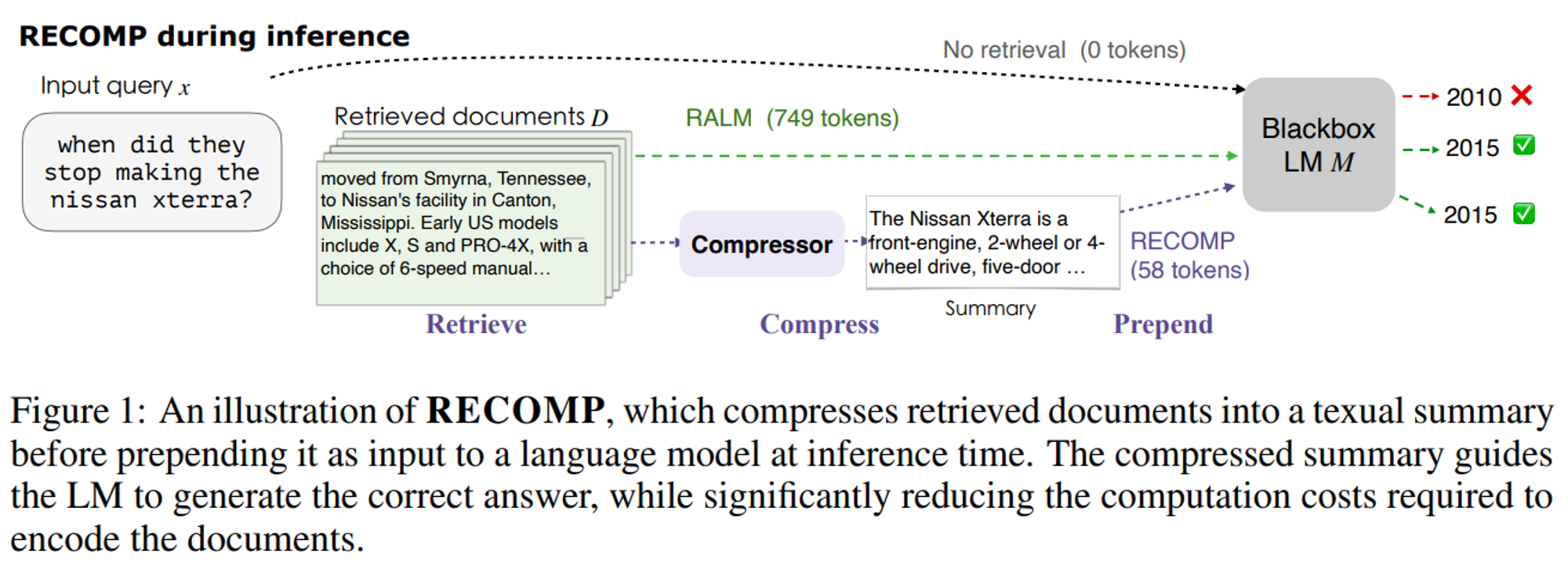
- Recomp
- extractive compressor: 유용한 문장을 선택
- abstractive compressor: 여러 문서에서 정보를 합성
- LongLLMLingua
- query와 연관된 key information에 초점을 맞춰 LLMLingua를 개선
- Selective Context
- 중복을 제거해 LLM의 효율성을 향상 (쿼리 기반이 아님)
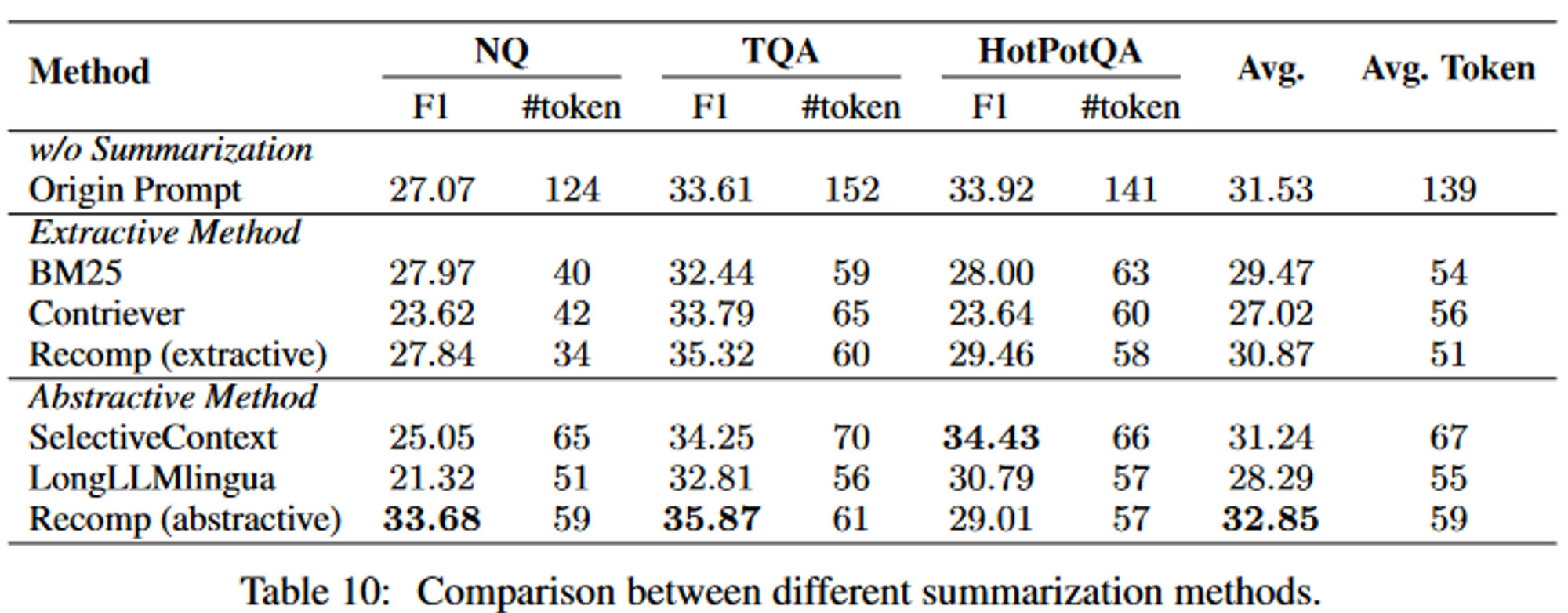
- 실험
- 데이터셋: NQ, TriviaQA, HotpotQA
- 실험 결과, Recomp을 추천
3.8. Generator Fine-tuning
→ Retriever fine-tuning은 다루지 않음
관련있는/없는 context가 generator에 미치는 영향을 알아보기 위함
x:query,D:context,y:ground−truthoutputx:query,D:context,y:ground−truthoutput
- Dg: query와 관련이있는 증강된 문서들 (Dg={dgold})
- Dr: 랜덤으로 sampling된 문서들 (Dr={drandom})
- Dgr: 관련 문서와 무작위로 선택된 문서 둘 다 (Dgr={dgold, random})
- Dgg: query와 관련된 문서 사본 두개 (Dgg={dgold, gold})
- D∅: retrival 없이 추론
- Mb: base model (not fine-tuned, Llama-27B)
- Mg,Mr,Mgr,Mgg: 각 Document에 fine-tuning된 모델
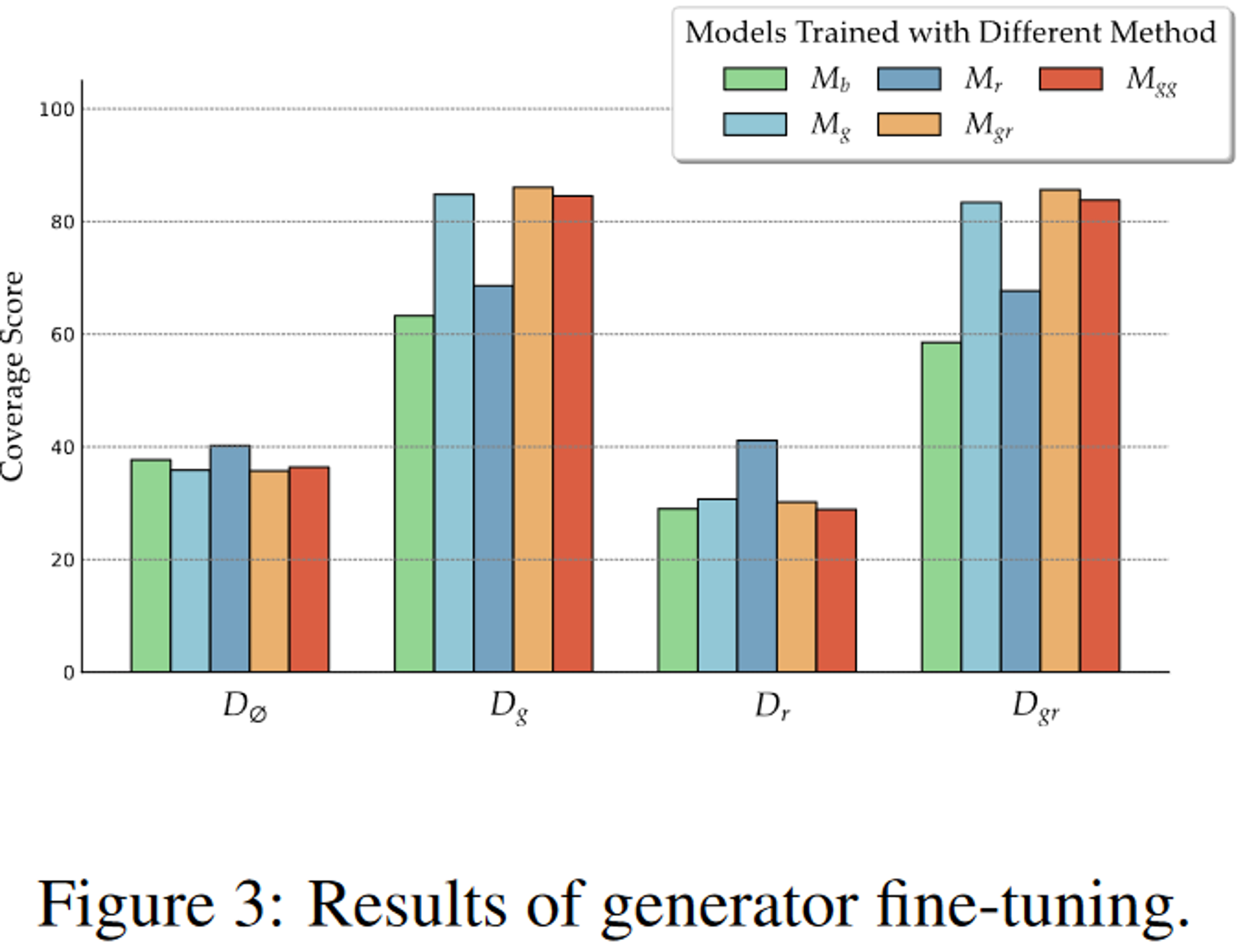
결과를 보면 Mgr이 gold, random이 제공되었을 때 가장 우수한 성능을 보임
→ 관련 없는 정보에 대해 retriever의 robustness를 향상시킬 수 있다고 봄
즉, 무작위 문서와 관련있는 문서를 같이 훈련시키는 것이 가장 좋은 방법임
4. Searching for Best RAG Practices
RAG를 구현하기 위한 최적의 방법
- Model: Llama2-7B-Chat model
- Random-selected and relevant documents로 fine-tuning됨 (3.8절)
- Vector Database: Milvus
- 1000만개의 위키백과 텍스트, 400만개의 의료 데이터 텍스트를 포함
4.1. Comprehensive Evaluation
- Tasks
- Commonsense Reasoning
- Fact Checking
- Open-Domain QA
- MultiHop QA
- Medical QA
- RAG → Faithfulness, Context Relevancy, Answer Relevancy, Answer Correctness
- Cosine similarity3, 4번의 경우, 토큰 수준에서의 F1 score과 Exact Match(EM) score를 사용
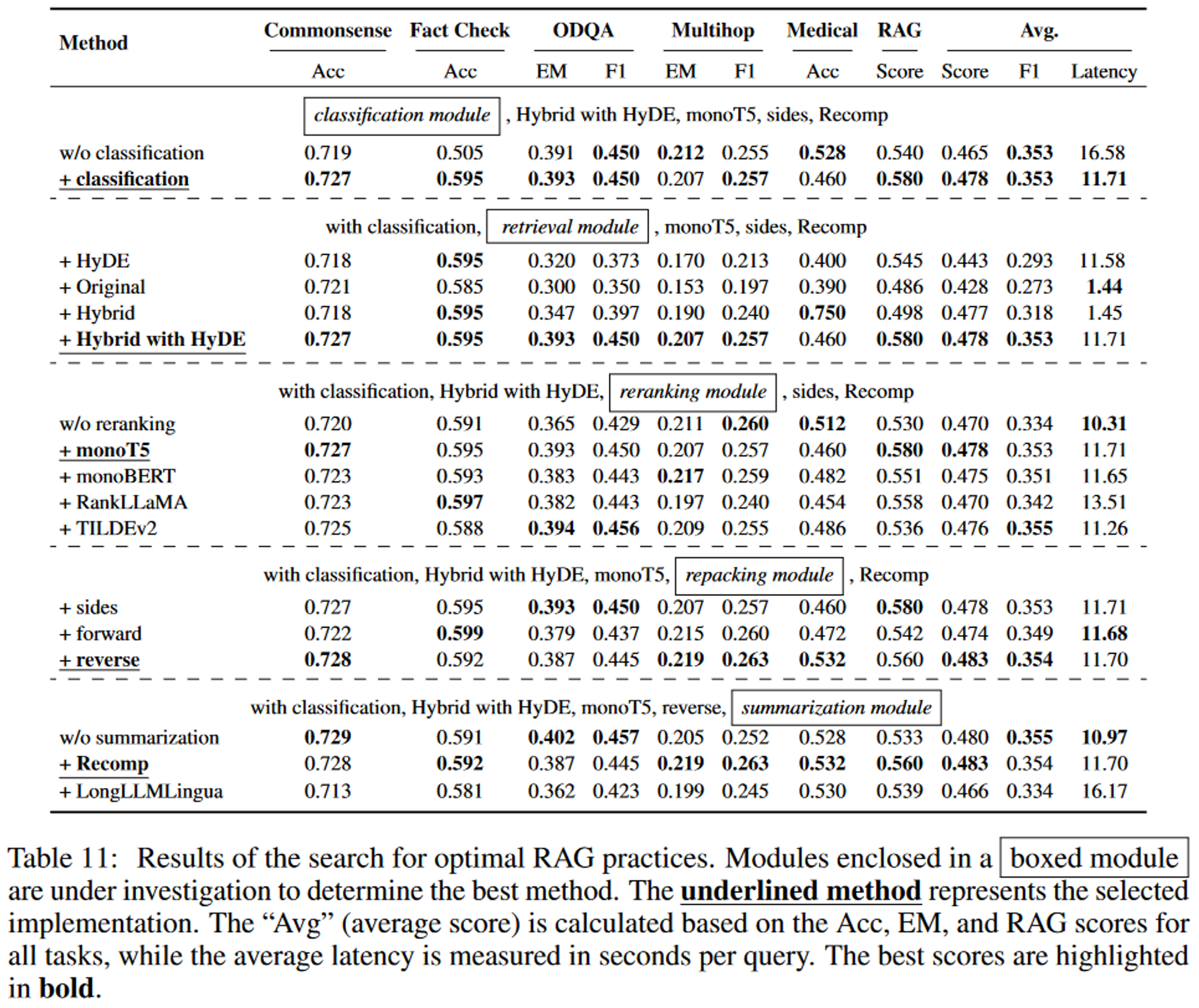
이를 통해 각 모듈이 RAG 시스템에서 성능에 고유하게 기여한다는 것을 보여줌
Query Classification module: 정확도 향상 및 지연 시간 단축
Retrieval & Reranking module: 다양한 query를 처리하는 시스템 능력을 향상
Repacking & Summarization module: 출력을 더 세분화해 고품질 응답을 보장
5. Discussion
5.1. Best Practices for Implementing RAG
두 가지 측면으로 Best practice를 정의할 수 있음
Best performance Practice
- Query Classification module
- Retrieval module: “Hybrid with HyDB”
- Reranking module: “monoT5”
- Repacking module: “Reverse”
- Summarization module: “Recomp”
→ 계산이 많지만, 가장 높은 average score인 0.483을 획득함
Balanced Efficiency Practice
- Query Classification module
- Retrieval module: “Hybrid”
- Reranking module: “TILDEv2”
- Repacking module: “Reverse”
- Summarization module: “Recomp”
→ Retrival module이 대부분의 시간을 차지하므로 Hybrid 방식으로 전환하면 비슷한 성능을 유지하면서 지연 시간을 크게 줄일 수 있음
5.2 Multimodal Extension
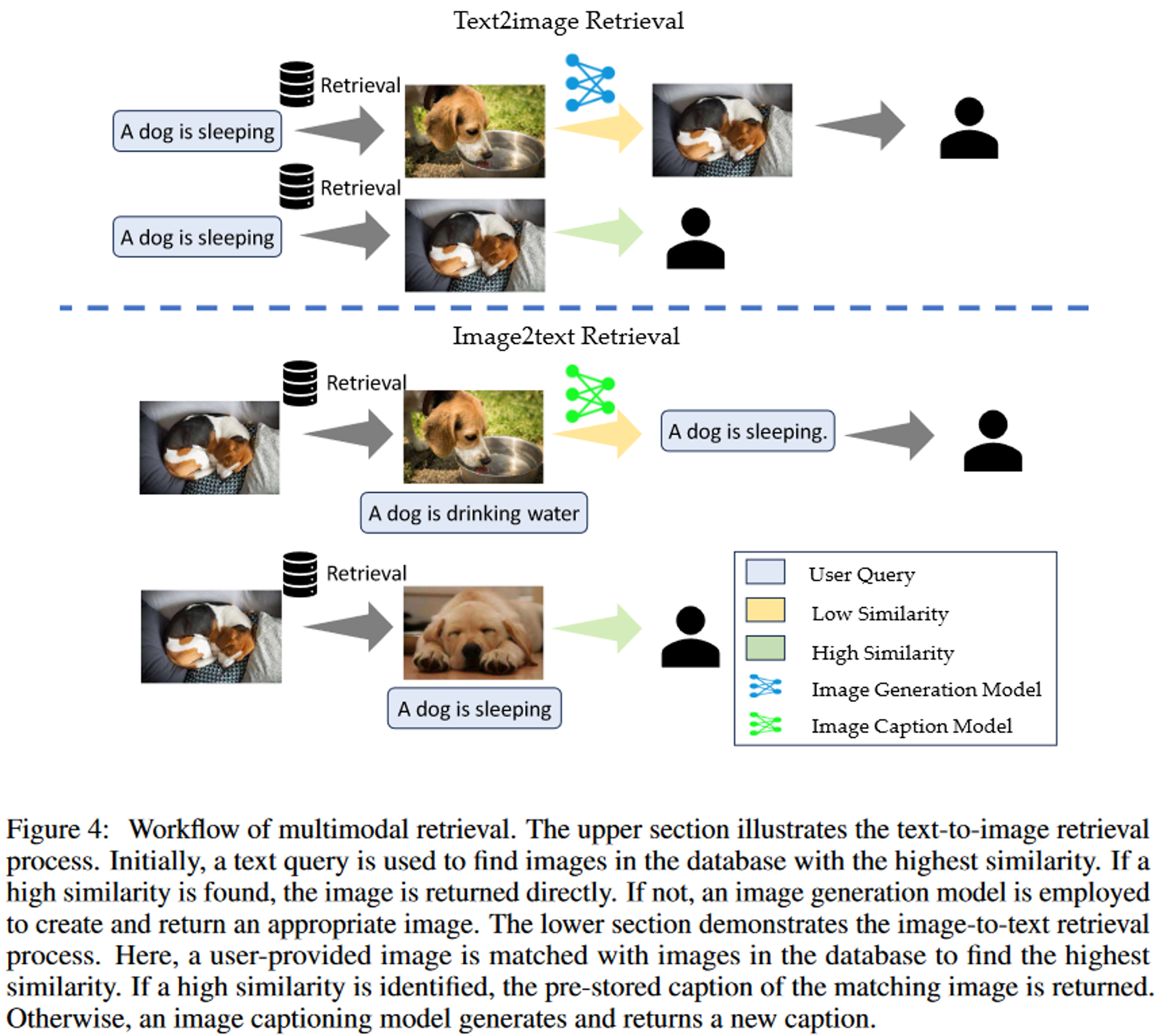
text2image
query가 이미지의 텍스트 설명과 일치할 때 이미지 생성 프로세스의 속도를 높임
image2text
사용자가 이미지를 제공하고 입력 이미지에 대한 대화에 참여할 때 작동
Advantage
- Groundedness (근거성) : 검증된 멀티모달 자료에서 정보를 제공 → authenticity와 specificity 보장
- Efficiency (효율성)
- 저장된 자료에 이미 답변이 존재하는 경우 효율적
- Maintainability (유지보수)
- 단순히 검색 소스의 크기를 확대하고 품질을 향상 → 새로운 요구 사항 충족 가
6. Conclusion
LLM에서 생성된 콘텐츠의 품질과 신뢰성을 개선하기 위해 RAG를 구성하는 최적의 방법을 파악
각 모듈에 대한 가장 효과적인 접근 방식을 추천함
모듈 결정을 위해 광범위한 실험을 수행함
향후 연구를 위한 토대를 마련하는데 도움을 줌
Limitations
다양한 청킹 기법이 RAG 시스템에 미치는 영향을 조사하지 못함