논문 정보
Xiting Wang, Kunpeng Liu, Dongjie Wang, Le Wu, Yanjie Fu, and Xing Xie. 2022. Multi-level Recommendation Reasoning over Knowledge Graphs with Reinforcement Learning. In Proceedings of the ACM Web Conference 2022 (WWW '22). Association for Computing Machinery, New York, NY, USA, 2098–2108. https://doi.org/10.1145/3485447.3512083
Multi-level Recommendation Reasoning over Knowledge Graphs with Reinforcement Learning | Proceedings of the ACM Web Conference 2
Overall Acceptance Rate1,899of8,196submissions,23%
dl.acm.org
Abstract
현재 KG는 정확도 향상을 위해 널리 사용되며 KG의 multi-hop path는 추천의 reasoning을 가능하게 한다.
본 논문에서는 ontology-view와 instance-view를 둘 다 활용해 다단계 추천 추론을 위한 강화학습 프레임워크를 제안한다.
해당 프레임워크는 high-level의 지식을 low-level로 효과적으로 이전해 더 나은 솔루션으로의 수렴을 보장하고, high-level, low-level의 개념중 자동으로 선택해 사용자의 interest를 더 잘 드러내는 추론 경로를 형성하는 multi-level reasoning path extraction method를 제안할 수 있다.
1. Introduction
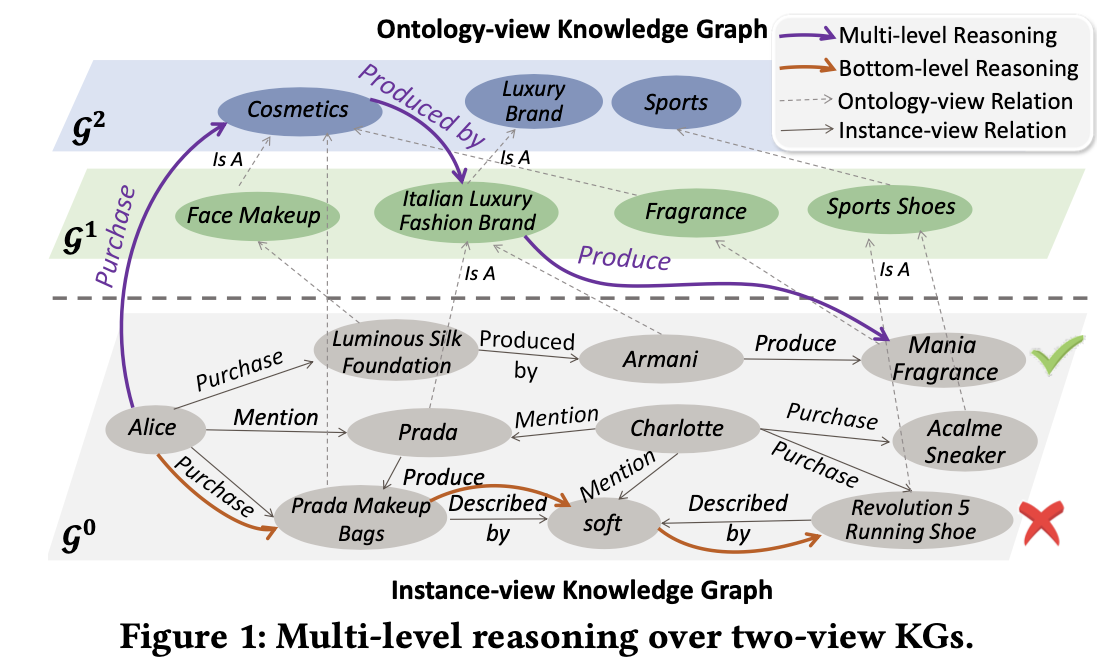
KG는 Alice Luminous Silk Foundation Armani Mania Fragrance
와 같이 multi-hop으로 명시적인 관계 모델링을 가능하게 할 수 있다는 점이 핵심이다.
하지만 기존 instance-view KG(g0만 볼 경우)는 high-level의 연결에 관한 정보가 부족하다.
e.g., alice는 armani와 prada 모두 user-item 수준에서 유추를 하지만 G1과 G2를 고려한다면 alice는 이탈리아 명품 브랜드에서 생산하는 코스메틱을 구매하는 경향이 있음을 알 수 있다. 이는 low-level에서 모델링을 진행하기 때문에 전체 패턴을 식별하기 어렵다.
문제점
- 추천 정확도가 저하된다.
- 사용자의 행동에 대한 전체적인 이해가 없을 경우, 단편화된 bottom-level reasoning process는 로컬에서의 최적 조건에 수렴할 확률이 크다.
e.g., category sports에 속하는 빨간 선의 아이템을 추천해줌
- 사용자의 행동에 대한 전체적인 이해가 없을 경우, 단편화된 bottom-level reasoning process는 로컬에서의 최적 조건에 수렴할 확률이 크다.
- botton-level reasoning path의 경우 사용자의 true interest를 드러내지 못할 수 있기 때문에 explainability가 제한적이다.
e.g., Italian Luxury Fashion brand
이를 해결하기 위해 instance view 외에 또다른 major type은 ontology view KG이다.
이는 entity 또는 high level이 다른 concept의 child인지 관계를 저장한다. (e.g., prada, is A, Italian Luxury Fashion brand)
ontology-view와 instance-view를 합치면 multi-level resoning over KGs를 달성할 수 있다.
만약 entity들에 대한 multi-level knowledge를 고려하여 reasoning path와 추천 아이템을 출력하는 경우, 추천시스템이 multi-level reasoning을 달성했다고 말한다.
인간은 다단계 정보처리 절차를 통해 추론을 하기 때문에 인간의 추론 과정을 multi-level reasoning model에 반영하여 P1과 P2와 같은 바람직한 특성을 식별함으로써 ML에 이러한 insight를 운영하고자 한다.
특히 사람은 일반적으로 개요를 얻은 다음, on demand로 세부 사항을 drilling하여 디테일을 얻어낸다.
e.g., alice가 어떤 high-level categories(화장품, 스포츠, ...)에 관심이 있는지 파악한다. 만약 화장품에 더 관심이 있다면 사람은 화장품 카테고리 측면에서의 insterest를 고려할 것이다.
Recommendation reasoning에서 이러한 top-down 전략은 거대한 search space에서의 가지치기를 도와주고, local minimum을 피하며 전체적인 사용자의 행동을 고려함으로써 더 만족스러운 솔루션을 수렴하는데 도움이 될 수 있다 -> P1
또한 human reasonin과 intention은 본질적으로 여러 수준의 세분성을 가지고 있다. (어떤 사람은 특정 명품 브랜드를 좋아하거나 모든 명품 브랜드를 좋아하거나)
따라서 보라색 선과 같이 multi-level에서 개념을 포함하는 multi-level reasoning path를 추론할 경우 사용자의 선호도를 올바르게 표현하는데 필수적인 flexibility를 제공하여 recommendation accuracy 와 explainability를 향상시킬 수 있다 -> P2
바람직한 특성 P1 및 P2를 가진 multi-level reasoning model을 설게하는 것을 어렵고, 기존의 supervised learning의 경우 추론 경로를 찾기 어렵다는 지적이 제기되었다.
1) 실제 레이블이 부족
2) 가장 좋은 경로를 찾기 위해 가능한 모든 추론 경로를 열거하는 것은 대규모 실제 KG에서는 불가능
single-level reasoning의 경우 RL의 Markov Decision Process(MDP)를 통해 명확해졌지만, Multi-level reasoning의 경우 RL의 설정에서 문제를 공식화하는 방법은 불분명하다.
Contribution
- Reinforcement learning framework for Multi-level recommendation Reasoning(ReMR)을 제안.
이는 추상적인 MDP를 기반으로 multi-level reasoning이 공식화될 수 있음을 보임 - Cascading Actor-Critic을 제안
top-down 전략을 채택하였고 high level의 KG의 지식이 low level reasoning 정책을 더 만족스러운 solution으로 이끄는 것을 보장한다. -> P1 - 각 hop에서 자동으로 어떤 reasoning path를 따라야할지 선택해주는 multi-level reasoning path extraction algorithm을 제안한다. 이는 user interest, accuracy와 explainability를 향상시킬 수 있다.
2. Preliminary

2.1 Multi-level Knowledge Graph
먼저 instance-view, ontology-view 이 두 타입의 KGs를 recommendation reasoning을 위해 사용한다.
두 KG를 결합한 형태를 Multi-level KG이라고 하며 이는 L+1 level의 의 형태를 갖는다.
아래에 있는 g0은 instance-view KG이며 이는 특정 entity 간의 관계를 나타내고있다.
이는 level 0으로 취급되며 entity set을 , relation set을 라고 한다.
g0에 있는 각 triplet은 으로 표기되며, 은 head entity, 은 relation, 은 tail entity를 의미한다.
이때, user-item 간 상호작용을 multi-hop reasoning path를 추론하기 위해 g0에 추가해야된다.(existing works 존재)
part는 ontology-view KG이며, 이를 설계하기 위해 low-level concept이 high-level의 concept의 하위 개념인지 여부를 보여주는 Is A 관계 8500만개를 가지고 있는 Microshoft Concept Graph를 활용한다.
해당 수식은 다음과 같이 표기한다.
여기서는 각 개념상 상위 1개의 부모만 고려한다.
2.2 Reinforcement Learning and MDP
supervised learning에서는 실측 정보 label이 필요하지만 reinforcement learning(RL)에서는 추가적인 learning paradigm이 제공된다. 이는 지능형 agent가 환경과 interacting하며 행동을 최적화하는 학습 패러다임을 제공한다.
상호작용은 다음과 같이 진행된다.
1. environment는 agent에게 current state를 알려준다.
2. agent는 policy하는 기능을 사용하여 상태에 따라 조치를 취한다.
3. environment는 업데이트가 되고, policy를 optimize한뒤 해당 조치에 따른 reward를 출력한다.
해당 agent의 목표는 누적된 reward를 최대화 하는 policy를 배우는 것이다.
Deep RL에서는 이 정책을 NN을 사용하여 모델링하고, 해당 프로세스는 policy가 수렴되거나, 최대 반복 회수에 도달할 때까지 반복된다.
RL의 환경은 전형적으로 MDPs의 형태로 결정되는데 MPD는 이다. 이때 S, A는 state space, action space이다.이때의 reward function 는 state-action pair의 곱으로 이루어져있다.
또한 는 state-action 쌍에서 다음 state로 전환될 확률을 의미한다.
M이 주어졌을 때, RL method을 사용하여 알 수 없는 search space와 current policy의 이용 사이의 균형을 찾을 수 있다.
뒤에는 종이로 읽어서 나중에 적기로,,,