
Introduction
기존의 연구들은 아래의 방법으로 모델을 선택한다고 합니다.
먼저 대규모 데이터셋으로부터 사전 학습 모델을 뽑아냅니다.
이후 fine-tuning 과정을 거칩니다.
(1) hyperparameter를 다양하게 설정
(2) 가장 accuracy가 높은 모델을 채택
여기서 여러 모델의 결과를 앙상블하는 방법이 하나의 싱글 모델을 선택했을 경우보다 더 뛰어는 경우도 있지만, computational cost가 많이 발생한다는 단점이 존재합니다.
본 논문에서는 사전 학습된 대규모 모델을 fine-tuning하는 맥락에서 해당 접근법의 두 번째 단계를 재평가하는데 중점을 두고 있습니다.
이를 통해 추가 추론이나 메모리 비용 없이 많은 모델의 가중치를 평균화하는 "model soups"을 제안합니다.
Method

먼저, input data \( x \)에 대한 neural network \( f(x, \theta) \)와 \( \theta \in R^d \)를 만족하는 파라미터를 \( \theta \)라고 합니다.
best on val. set은 한 parameter에 대해서 validation set으로 accuracy를 뽑았을 때 best selection인 경우, Ensemble은 k개의 parameter로 부터 나온 k개의 모델들을 ensemble한 경우이며 이는 computation cost가 O(k)가 소요되며
uniform soup은 ensemble과 달리 hyperparameter를 평균내어 평균낸 hyperparamter를 함수에 넣어 계산하게 됩니다!
해당 두 경우보다 본 논문에서 제안하는 방법을 쓸 경우 성능이 더 괜찮게 나오고, cost도 O(1)이 든다고 합니다.
하지만 uniform soup은 낮은 accuracy를 가진 모델들도 포함이 될 수 있어 전체적으로 성능이 좋아지지 않을 수 있다는 단점이 존재합니다.
정확도가 낮은 모델들이 포함되는 unique soup의 문제를 greedy soup(Recipe 1)으로 회피할 수 있다고 합니다.

greedy soup의 알고리즘은 다음과 같이 진행됩니다.
먼저 validation set으로 부터 accuracy가 측정된 k개의 model들을 accuracy 기준으로 정렬을 진행해줍니다.
또한 ingredients set을 {}으로 초기화를 해준 뒤, ingredients를 평균낸것의 ValAcc와 비교하였을 때, k번째 parameter를 포함해서 쳥균낸 것의 ValAcc와 비교하였을 때 포함한것이 더 클 경우에만 ingredients set에 포함을 시켜줍니다.
해당 방법을 반복하게 되면 낮은 accuracy를 가지는 모델을 포함하지 않게 되고 따라서 uniform soup의 문제점을 해결할 수 있게 됩니다.
세 번째로 Learned soup은 model들을 선택할 때 gradient-based minibatch optimization을 통해 선택하게 됩니다.
이 방법이 Learned soup이라 불리는 이유는 각 ingredients에 대한 soup mixing coefficient를 포함하고 있기 때문에 learned soup이라 불립니다.
하지만 이는 모든 모델을 메모리에 동시에 load해야한다는 단점이 존재합니다.
loss \( l \)과 validation set \( \{ (x_i, y_i)\}^n_{i=1}\)이 있을 때, mixing coefficient는 아래의 수식을 통해 얻게됩니다.

먼저 \( \alpha \)는 softmax의 결과이며, \( \alpha_i \)는 양수이며 합은 1입니다.
이를 Adam W와 lr=0.1을 사용해 validation set에 대해 3 epoch에 대해서 gradient based mini-batch optimization을 적용하여 최적화를 진행합니다.

Table 3을 보면 "by layer"을 사용해 다양하게 learned soup 실험을 진행하였는데 이 경우 각 layer에 대해서 별도의 \( \alpha \)를 학습했다고 합니다.
마지막으로 non-uniform mixing coefficient를 얻는 방법은 greedy soup에서 sample을 추출하는 것이라고 합니다.
이러한 model soups에서 제안하는 방법을 쓸 경우 추가적인 computational cost가 발생하지 않고, 1개의 모델을 inference할 때와 동일한 cost가 발생한다는 장점도 있다고 합니다.
Experiments
1. Experimental setup
해당 논문은 fine-tuning을 진행할 때 model soups을 적용하여 실험을 진행하였습니다.
해당 논문에서 fine-tuning을 진행하는 주요 모델은 image-text pairs의 대조적인 supervision으로 pre-trained된 CLIP, ALIN, BASIC, JFT-3B에서 pre-trained된 ViT-G/14, text classification을 위한 trasformer 모델로 진행이 됩니다.
이는 end-to-end로 수행되며 final linear layer만 훈련하는 것보다 accuracy가 더 향상된다고 합니다.
여기서 final linear layer를 초기화하는 두 가지 방법이 있습니다.
1. Linear probe(LP)에서 모델을 초기화
2. Zero-shot 초기화(e.g., CLIP or ALINE의 text tower에서 생성된 분류기를 초기화로 사용)
따로 언급하지 않는 경우 1번을 사용한다고 합니다.
ensemble baseline의 경우, model의 logits(unormalized outputs)을 앙상블하게 됩니다.
mini-batch는 cross-entropy loss를 사용하게 되고, 따로 언급하지 않는 경우 ImageNet에서 수행한다고 합니다.
ImageNet에서 fine-tuning을 할 경우 ImageNetV2, ImageNet-R, ImageNet-Sketch, ObjectNet, ImageNet-A의 다섯가지 분포 이동에 대해 평균화한 결과를 제공합니다.
이때 validation set은 train set 중 2%를 greedy soups을 구성하기 위해 사용하였다고 합니다.
2. Intution and motivation
Error landscape visualizations
이 방법이 가능한 이유는 하나의 pre-trained 모델에서 fine-tuning을 할 경우 독립적으로 optimization된 모델들은 loss의 landscape를 공유하여 동일한 basin으로 가기 때문이라고 합니다.

\( \theta_0 \in R^d \)는 pre-trained된 모델이며 각 화살표의 끝은 다른 방법으로 fine-tuning한 결과입니다.
imageNet test error에서 \( 3\times 10^{-6} \)인 경우와 \( 3\times 10^{-5} \)인 경우의 평균을 낼 경우

평균낸 결과가 성능이 기존 모델들보다 더 적절한 부분에 도착할 것이라고 예상할 수 있습니다
그래서 이는 weigth를 interpolating하는 것이 accuracy를 더 높일 수 있다고 말할 수 있습니다.
여기서 \( \phi \)를 \( \theta_0 \)와 분홍색 원 사이의 벡터, \( \theta_0 \)와 파란색 네모 사이의 벡터끼리의 사잇각이라고 했을 때,
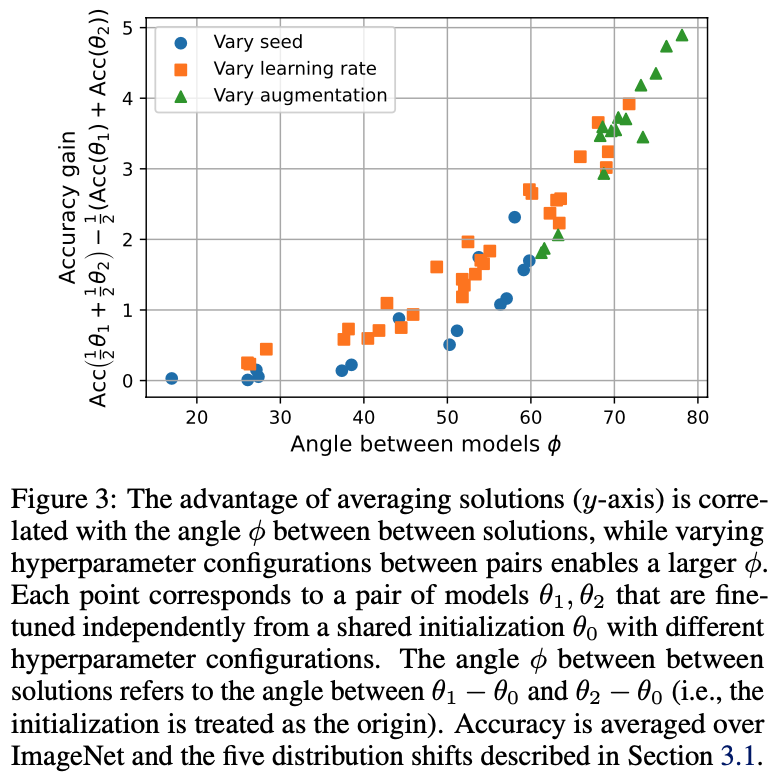
Figure 3에서는 angle \( \phi \)가 더 클수록 accuracy gain이 더 크다는 것을 보여줍니다.
즉, \( \phi \)가 크면 interpolating을 진행했을 경우 얻는 이득이 더 크다는 것을 의미하게 됩니다.
따라서 해당 결과는 다음 두 가지를 나타내고 있습니다.
(1) 두가지 fine-tuned solutions을 보간하면 두 모델들에 비해 더 높은 accuracy를 얻을 수 있다.
(2) 연관이 없는 solutions(사잇각이 90도에 가까운 모델들)을 많이 사용하면 선형 보간 경로에서 더 높은 accuracy를 얻을 수 있다.
Ensemble comparison
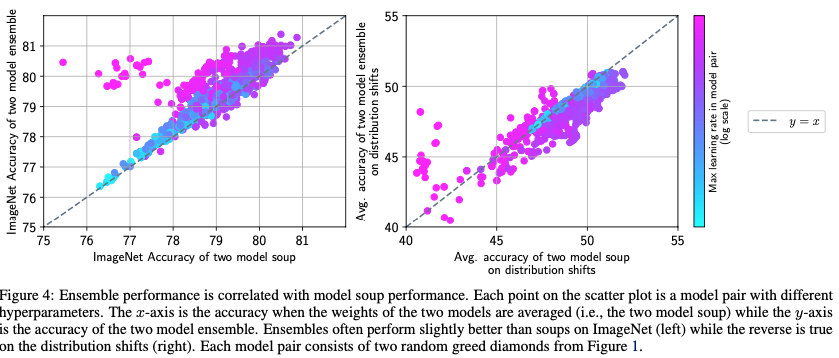
Figure 4는 ensemble performence와 soup performance와 상관관계가 있다는 것을 볼 수 있습니다.
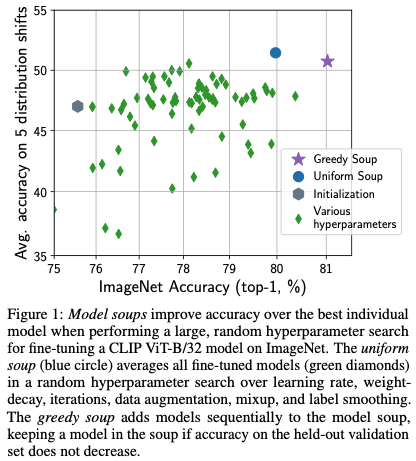
그림 1을 보면 various hyperparameters의 경우 다양한 hyperparameter로부터 얻어진 모델들의 accuracy를 나타내고, 가장 오른쪽에 있는(accuracy: 80~81%) 모델이 가장 성능이 우수한 모델임을 알 수 있습니다.
이때 uniform soup은 다양한 hyperparameter를 평균내어 fine-tuning을 진행하였는데 이는 성능이 더 좋지 않은 모습을 볼 수 있습니다.
또한 greedy soup의 경우 앞에서 설명한 모델들보다 더 우수한 성능을 나타내는 모습을 확인할 수 있습니다.
여기서 개별 solution에 대해 임의로 선택된 model의 쌍을 고려하고 해당 쌍에서 모델의 최대 학습률에 따른 ensemble accuracy과 soup accuracy 사이의 관계를 발견합니다.
1. low lr ->둘의 accuracy가 유사하지만 suboptimal하다.
2. moderate lr -> ensemble accuracy, soup accuracy가 둘 다 높다.
3. high lr -> ensemble accuracy가 soup accuracy보다 높음
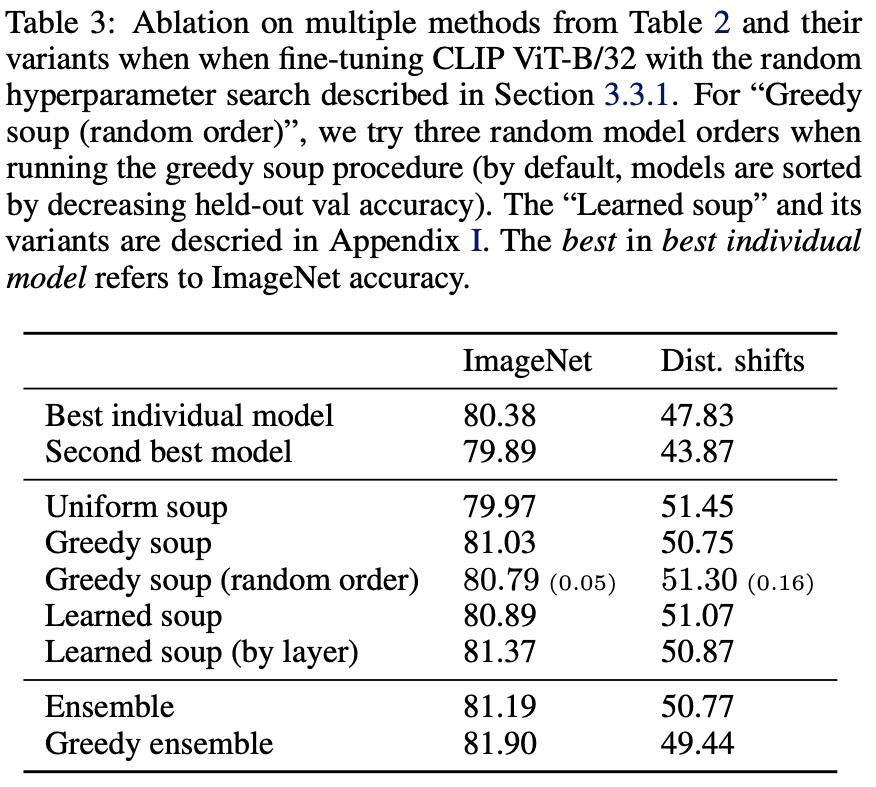
다시 Table 3을 보게 되면 best individual model의 경우 Figure 1에서 80~81%의 accuracy를 가지는 model을 의미하게 되고, 두 번째로 높은 성능을 가지는 model의 경우 79.89% accuracy를 가지게 됩니다.
이때 uniform soup의 경우 ImageNet에서는 Best individual model보다 성능이 더 낮은 모습을 볼 수 있고, greedy soup이 best individual model보다 accuracy가 더 높다는 것을 볼 수 있습니다.
greedy soup(random order)는 greedy soup이 초반에 각 parameter에 대한 ValAcc를 기준으로 sorting을 하고 시작하는데 sorting 대신 random으로 섞은 이후 다음 과정을 진행한 것을 의미합니다.
이 경우 sorting을 했을때보다 accuracy가 더 낮게 나온 결과를 보고 있습니다.
또한 앞에서 언급했듯이 Learned soup은 gradient-based minibatch optimization를 통해 model을 선택한 것인데 ImageNet에서는 greedy soup보단 낮은 결과를 보여주었지만 by layer의 경우 greedy soup보다 높은 accuracy를 보여주었습니다.
그리고 ensemble의 경우 greedy soup보다 높은 accuracy를 보여주었습니다. 하지만 본 논문의 저자는 ensemble의 accuracy가 더 높을지언정 greedy soup은 k개의 model이 있어도 \( O(1) \)의 cost를 보여주는 반면, ensemble은 k개의 model을 다 구해야 되기 때문에 computational cost가 더 많이 발생한다고 강조하고 있습니다.
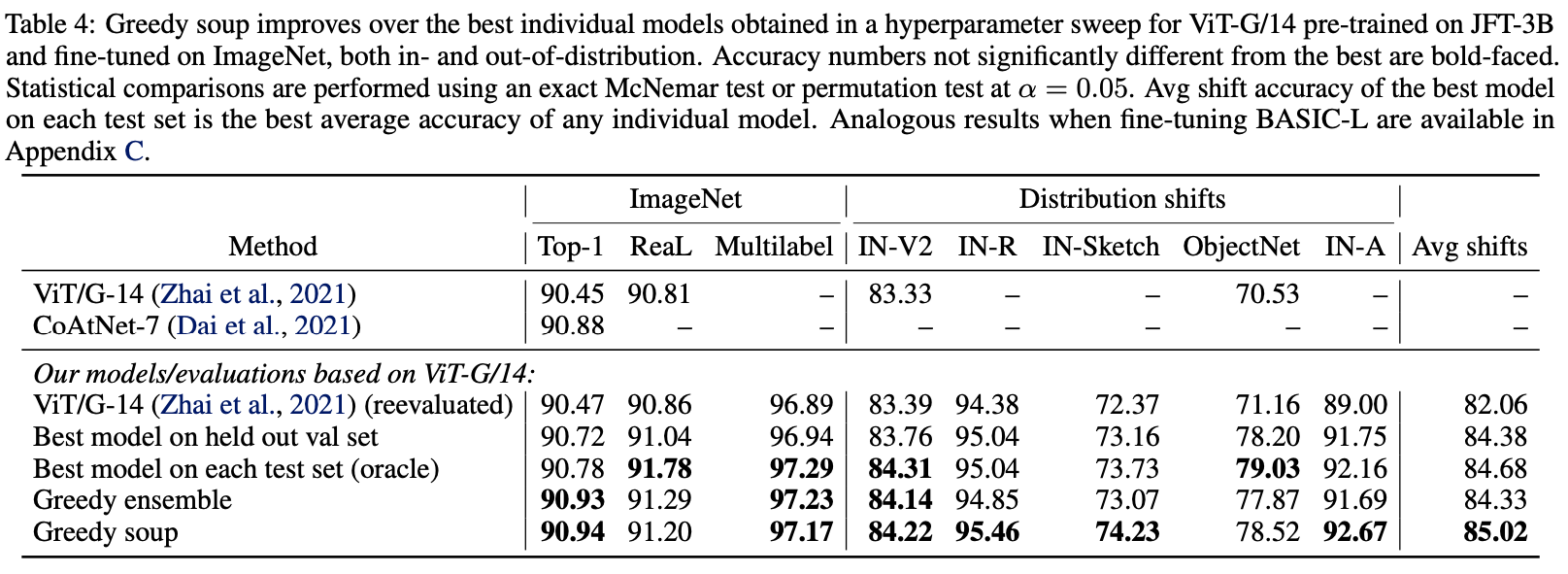
Table 4는 Distribution shifts에 대한 더 자세한 표를 나타내는데 이는 Top-1, ReaL, Multilabel의 ImageNet과 앞에서 언급한 5개의 분포 shfit dataset에 대해 점수를 측정한 표입니다.
결과적으로 greedy soup이 ObjectNet을 제외한 나머지에서 전부 우수하다는 것을 볼 수 있습니다.

이를 Text Classification task에서도 fine-tuning을 진행했습니다.
여기서 MRPC, RTE, CoLA, SST-2는 GLUE를 benchmark한 text classification task입니다.
결과적으로 Best individual model보다 Greedy soup의 performance가 더 좋거나 같은 것을 보아 greedy soup을 사용해 비교적 성능을 더 높게 향상시키는 것이 가능하다고 합니다.
Conclusion
본 논문에서는 fine-tuning을 할 때, 보류된 validation set에서 best model을 선택하는 기존의 절차에 대해 새로운 방법을 제안합니다.
결과적으로 inference 중, 추가적인 계산 없이 여러 fine-tuned solutions의 가중치를 평균화해 더 나은 모델을 생성하는 model soups을 제안하였습니다.
Appendix
몇개만 적어보겠습니다..
B. Additional figures
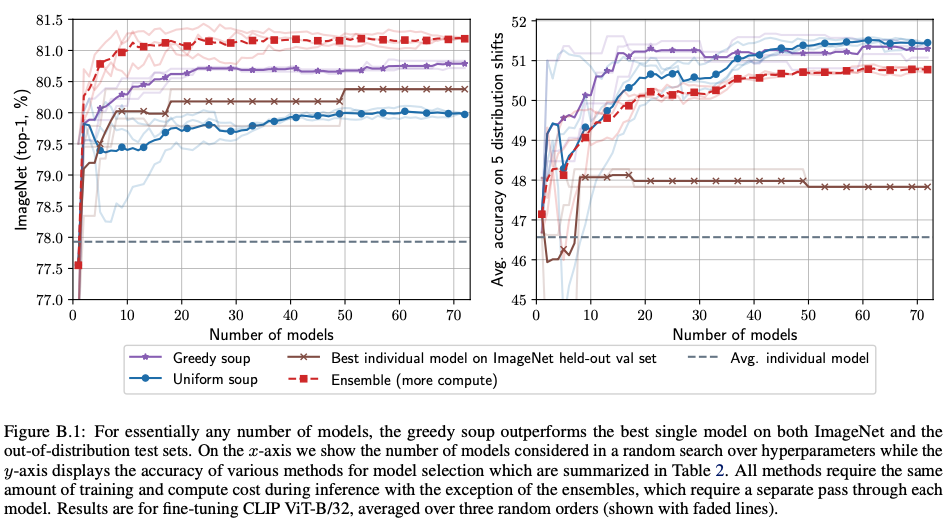
해당 figure는 모델을 훈련시키는데 필요한 모델 수를 x축으로 하였을 때의 Accuracy를 나타내는 그래프입니다.
왼쪽 ImageNet의 경우 Emsemble이 가장 빨리 학습되고 정확도가 높은 모습을 볼 수 있습니다.
반면 오른쪽을 보면 ensemble보다 greedy soup이 더 빠르게 accuracy가 올라가고 성능도 더 좋다는 것을 볼 수 있습니다.
C. BASIC
위에서 zero shot을 언급했는데 여기서 쓰입니다.
BASIC-L을 fine-tuning할 때 model soup을 테스트해봤다고 합니다.
해당 결과는 아래의 표와 같습니다.
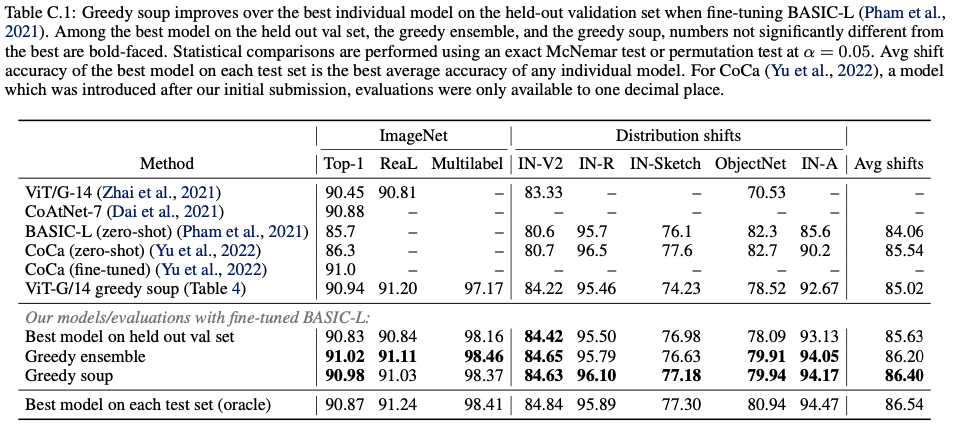
(zero-shot classification이란, unseen된 training할 때 보이지 않았던 class를 예측하는 것입니다.)
D. Robust fine-tuning
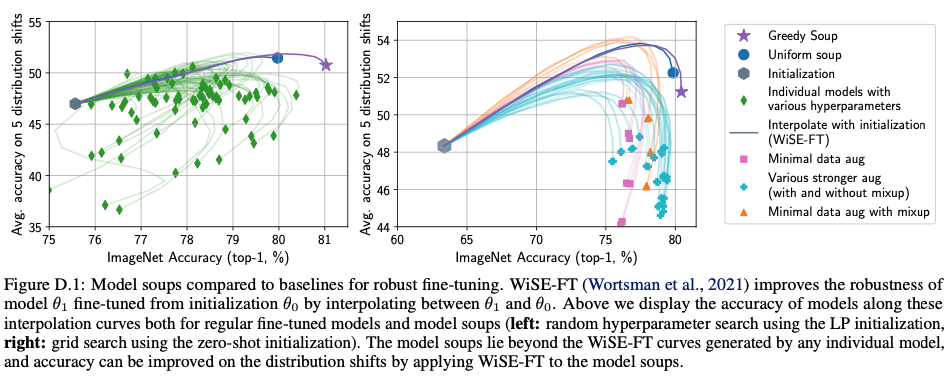
\( \theta_1 \)과 \( \theta_0 \)을 선형 보간하여 initialization \( \theta_0 \)에서 fine-tuning된 모델 \( \theta_1 \)dml robustness를 향상시키는 방법이 WISE-FT입니다.
위의 그림이 \( \theta_1 \)과 \( \theta_0 \) 사이를 보간할 때, CLIP ViT-B/32를 fine-tuning할 때 standard grid search를 위해 곡선을 추적한다고 합니다.
standard gird search는 lr이 \( 3\times 10^{-5} \), \( 2\times 10^{-5} \), \( 1\times 10^{-5} \), \( 3\times 10^{-6} \) 이 포함되고 \( 2\times 10^{-5} \), \( 1\times 10^{-5} \) 일 경우 가장 성능이 좋다고 합니다.
이외에도 extream grid, random search가 존재합니다.